Hi, I’m Janvi, a Software Engineer at Coda. I’m excited about the applications of generative AI, and especially Coda AI.
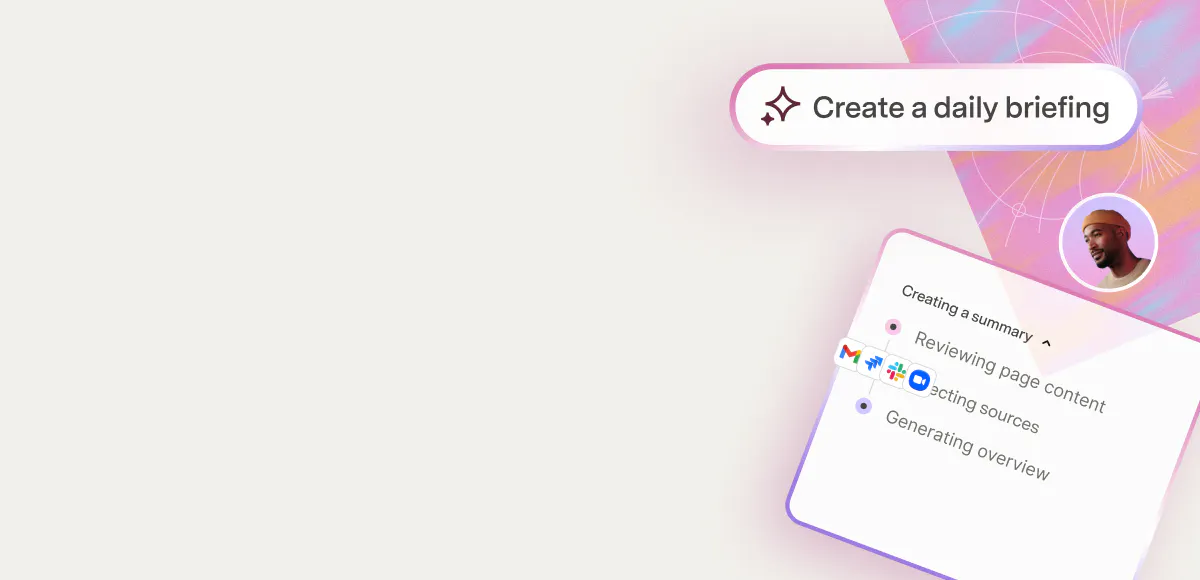
Within the last few months, I’ve watched ChatGPT, DALL-E, and GPT-4 take the internet by storm. Even though AI research has been around for 80 years, the latest developments have captured the curiosity of millions inside and outside the tech industry, finally making AI mainstream #basic. The access to large language models has caused a surge in AI development for both large companies and startups: one in every five companies in Y-Combinator’s 2023 winter cohort built in the generative AI space. Knowing that AI is going to be widely available across many tools inspired me to learn more about how it works, and why generative AI has become so disruptive. If you are also interested in having a deeper understanding of how the latest machine learning models work, this post is for you. This article aims to establish an intuition around key machine learning terms to demystify some of the inner workings of these developments. Ever wondered how computers understand concepts that humans perceive with our senses, like language and images? For example, when users input text into ChatGPT, how does it understand what the user is saying? Embeddings. Computers don’t understand English; they understand numbers, vectors, and matrices. Embeddings are a way to map concepts to meaningful numbers. “Meaningful” in that similar concepts are physically close to each other on a graph. For example, if you want to build a movie-recommendation model, you would need a way to embed movies. A potential embedding could consider where movies lie on a graph defined by kid-friendliness and humor: Voila, the movie The Hangover can now be meaningfully represented by numbers. Based on this representation, if you’ve watched The Hangover, the recommendation system is more likely to recommend The Incredibles to you than Soul, because it’s closer on the graph. It is a pretty bad recommendation, but hey, it’s a start. To properly represent a movie, many more traits would need to be represented, resulting in a longer embedding vector. In GloVe, an online package with embeddings for English words used in Wikipedia, the embedding for the word “king” is a 50-digit vector:Source: jalammar word2vec
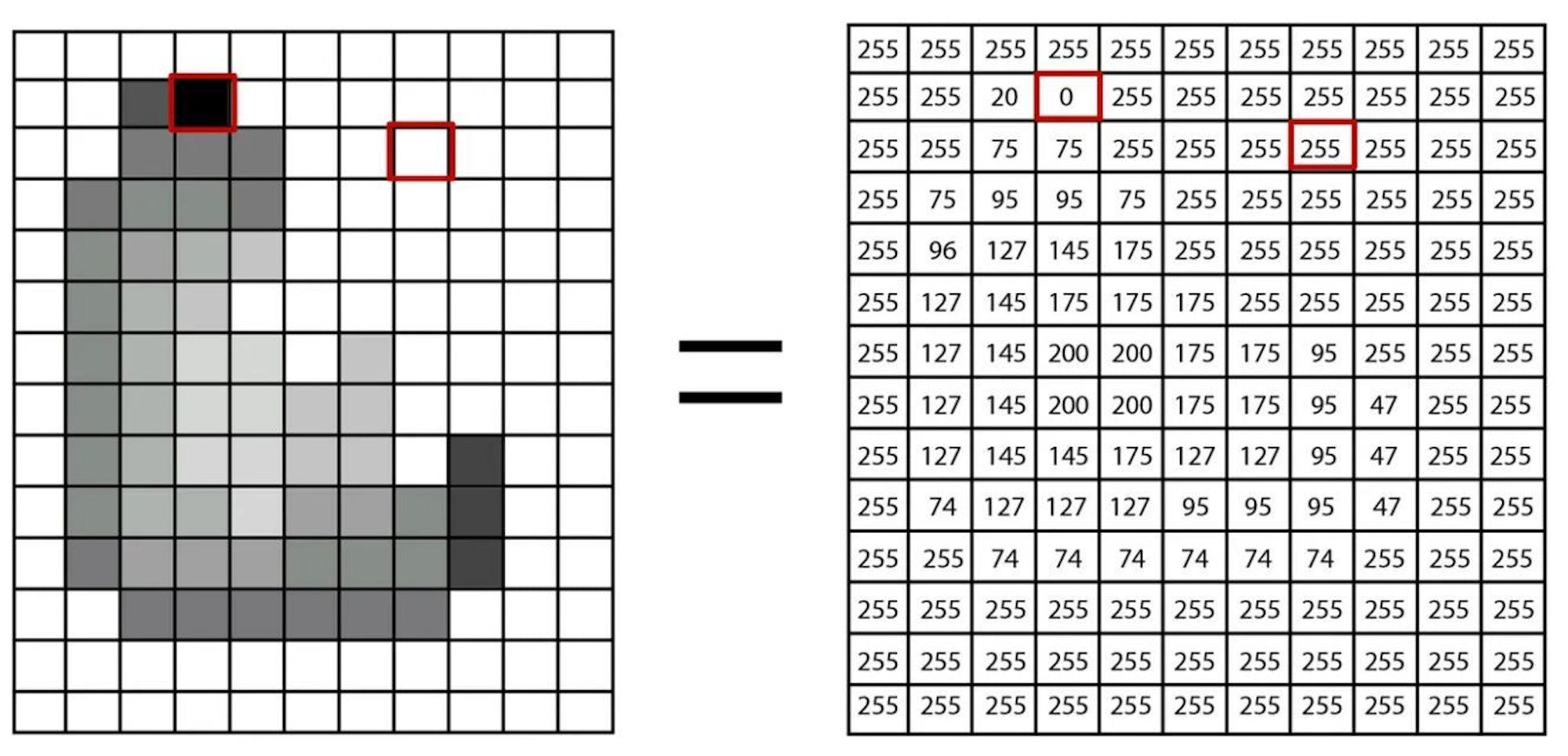
Images require embeddings as well. One very basic way to embed images is to represent each pixel by its color. Now an image is just a matrix of numbers like so:
source: Romain Beaumont’s Medium
Comparing tokens to embeddings
How iPhone identifies plants
To wrap up the discussion on models, let's consider how an iPhone can identify the species of plants/animals in your photos. It’s a pretty cool feature if you haven’t used it before: I used to think that Apple was comparing my image to millions of other images of plants and animals and identifying the closest match, a huge computational feat. 😵💫 That is not what is happening. Apple has already trained a model that is good at identifying species on powerful computers. After the training is complete, they are left with a complicated equation (a model) that accepts photos as inputs. This model is either stored locally on my phone or on the cloud depending on whether the species-identification feature needs to work offline or not. When I use this feature, my image gets inputted into this model. The photo gets tokenized, and each token gets embedded and turned into vectors. Then, a bunch of linear algebra functions happen with the parameters chosen during training, finally returning the species. 🌱
Source: Hugging Face LLMs
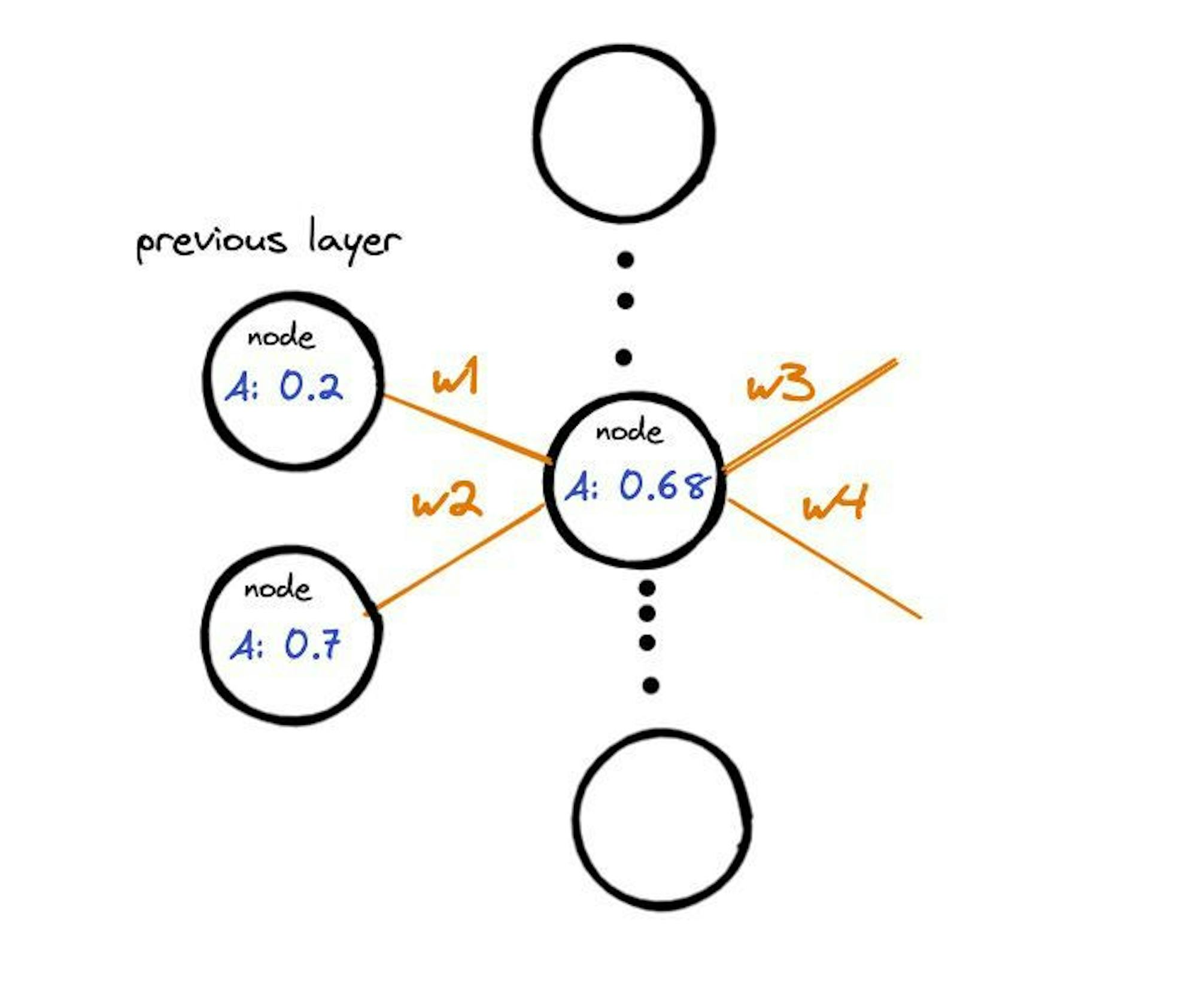
Diagram of a neural network
Looking at how the data gets passed between nodes in each layer, every node in the neural network has a value between 0 and 1, called activation. The activation is the sum of the weights and activations from the incoming nodes in the previous layer. If the activation is below a threshold value, the node passes no data to the next layer. If the number exceeds the threshold value, the node “fires,” which means it passes the processed data to all its outgoing connections.