








Tables, not spreadsheets
Real applications need real tables.


Matt Hudson
Head of Strategy & Insights at Coda
Tables, not spreadsheets
By Matt Hudson
Share this article



Blog > Productivity · 7 min read

Why relational databases?
They were a new fundamental enabling layer that changed what computing could do. Before relational databases appeared in the late 1970s, if you wanted your database to show you, say, 'all customers who bought this product and live in this city', that would generally need a custom engineering project. Databases were not built with structure such that any arbitrary cross-referenced query was an easy, routine thing to do. If you wanted to ask a question, someone would have to build it. Databases were record-keeping systems; relational databases turned them into business intelligence systems. This changed what databases could be used for in important ways, and so created new use cases and new billion dollar companies. Relational databases gave us Oracle, but they also gave us SAP, and SAP and its peers gave us global just-in-time supply chains - they gave us Apple and Starbucks. By the 1990s, pretty much all enterprise software was a relational database - PeopleSoft and CRM and SuccessFactors and dozens more all ran on relational databases. No-one looked at SuccessFactors or Salesforce and said "that will never work because Oracle has all the databases" - rather, this technology became an enabling layer that was part of everything.

Some simple spreadsheet formulas using R1C1 notation
- Where do formulas live? Do formulas live in cells like they do in a spreadsheet, or are they defined at the column or row level? Would we support formulas on the canvas?
- What is the reference model? Do formulas use an object name (e.g. the name of a table or column) or refer to a location (e.g. the position of a cell ー is it geometric)? Is there a workable hybrid where you point to a location, but pretty print with the names of the object in that spot (a la Apple’s Numbers)?
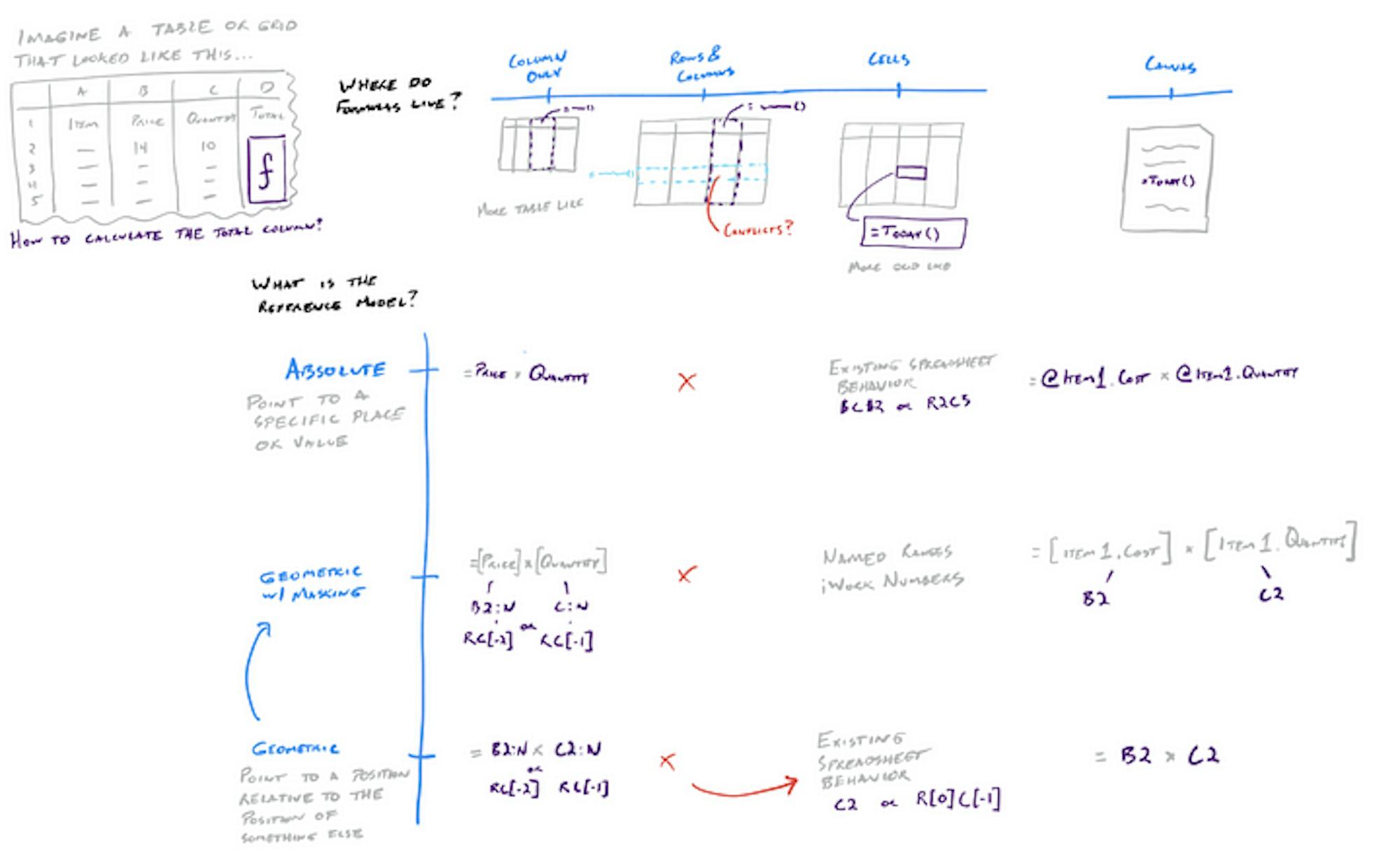
The original sketch of the options for formulas in tables vs spreadsheets
A simple table with a chart view and a calendar view
A canvas formula that counts the number of open tasks in the table
Column types enable our formula autocomplete to make type specific recommendations
The way a projection is done in a spreadsheet using a VLookup
The way a projection is done in Coda, using a Lookup column
Getting a cell value in Coda through the @ref