Enable edits on sync tables¶
Sync tables allow you to pull in data from external applications and sources, but by default these tables are read-only. You can make your sync tables more useful by supporting two-way sync, where you allow users to edit the cell values and push the changes back to the data source.
Using two-way sync¶
To enable two-way sync on a sync table that supports it you need to toggle on the option Enable Edits in the sync table settings. Doing so reveals additional options that control when updates are sent and which account is used.
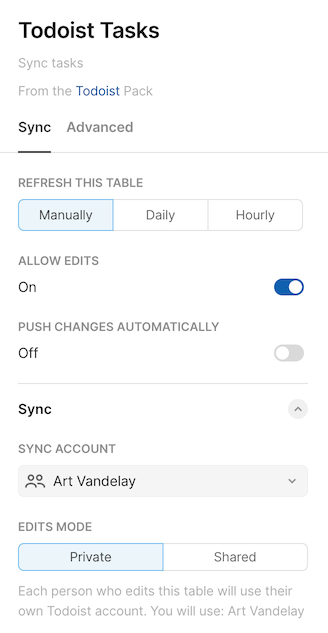
Certain columns of the table will now be editable, and you can change cell values them as you would for a normal Superhuman Docs table. Use the Update rows link to push the changes back to the data source.
Adding two-way sync¶
You can add support for two-way sync to any sync table, even after it's published. You'll have to adjust the schema used by your sync table and add a function to handle the updates.
Annotate the schema¶
Not every field that you sync from the external data source can be changed. To indicate which columns should be editable you need to annotate your schema by adding mutable: true to the corresponding properties.
const TaskSchema = sdk.makeObjectSchema({
properties: {
name: {
description: "The name of the task.",
type: sdk.ValueType.String,
fromKey: "content",
mutable: true,
},
// ...
},
// ...
});
Only top-level properties in the schema are eligible to be editable, since they are stored in distinct columns. Properties in nested objects, even if marked as mutable, will not be editable in the sync table. You can however still make a column containing an nested object editable, but you'll need to provide an options function to generate a list of compatible objects.
Annotating a shared schema
If the property's schema is reused in multiple columns, and only some of those are editable, you can use the object spread operator to duplicate the schema and merge in the mutable field.
const UserSchema = sdk.makeObjectSchema({
// ...
});
const TaskSchema = sdk.makeObjectSchema({
properties: {
// The creator cannot be edited.
creator: UserSchema,
// The assignee can be edited.
assignee: {
...UserSchema,
mutable: true,
},
// ...
},
// ...
});
Write the update function¶
Once the user has made their edits you'll need to figure out how to push them back to the external data source. This code is implemented in the executeUpdate function, which lives alongside the execute function in the sync formula.
pack.addSyncTable({
name: "Tasks",
// ...
formula: {
// ...
execute: async function (args, context) {
// Pull down the data ...
},
executeUpdate: async function (args, updates, context) {
// Push up the changes and return the updated data...
},
},
});
Much like the execute function, the executeUpdate function receives the sync table's parameter values and the execution context. However it is also provided an array of updates which contain information about the rows being updated.
Each SyncUpdate object in the array contains the previous value for that row, the new value, and the list of fields that were updated. By default the executeUpdate function only receives one row at a time, but this can be increased for APIs that support batching.
Use those values to make the API requests needed to update the external data source, and then return the final value for the updated row. This may differ from what the user entered if the update had side effects, for example increasing the last updated timestamp of the record.
executeUpdate: async function (args, updates, context) {
let update = updates[0]; // Only one row at a time, by default.
let task = update.newValue;
// Update the task in Todoist.
let response = await context.fetcher.fetch({
method: "POST",
url: `https://api.todoist.com/rest/v2/tasks/${task.id}`,
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(task),
});
// Return the final state of the task.
let updated = response.body;
return {
result: [updated],
};
},
Getting the final row value
For many APIs getting the final row value is easy, as the updated record is returned in the API response. In cases where the updated record isn't returned in the response you can immediately fetch it to get the final state.
let task = update.newValue;
await updateTask(task);
let updated = await getTask(task.id);
return {
result: [updated],
};
This may not always be feasible however, as some APIs have a delay between when the update is made and when it's reflected in the API responses. In those cases you may have to return the value that the user entered, understanding that any side effects from the update won't be reflected.
let task = update.newValue;
await updateTask(task);
return {
result: [task],
};
Transforming row values¶
While needed for all sync tables, when implementing two-way sync you need to pay extra attention to how you transform row values between the form used by the API and that used by the table. This is not an issue if your sync table schema exactly matches the items returned by the API, but often you want or need a different representation of the data in Superhuman Docs.
When possible, utilize the fromKey field of property schemas to allow the platform to automatically map between the API results and the table columns. This works not only when syncing in rows in the execute function, but also in reverse when sending updates in the executeUpdate function. Specifically, the SyncUpdate object's newValue, previousValue, and updatedFields will all be keyed using the fromKey value if set.
Using fromKey to transform automatically
const TaskSchema = sdk.makeObjectSchema({
properties: {
id: { type: sdk.ValueType.String },
// Map the API's "content" field to the property "name".
name: { type: sdk.ValueType.String, fromKey: "content", mutable: true },
},
// ...
});
pack.addSyncTable({
name: "Tasks",
schema: TaskSchema,
// ...
formula: {
// ...
execute: async function (args, context) {
let tasks = await getTasks(context);
// Each task looks like: {"id": "123", "content": "Foo"}
// The platform will automatically map the "content" field to the
// "name" property.
return {
result: tasks,
};
},
executeUpdate: async function (args, updates, context) {
let update = updates[0];
let task = update.newValue;
// The new value looks like: {"id": "123", "content": "Bar"}
// The platform automatically mapped "name" property back to
// "content".
task = await updateTask(context, task);
// The final value will look like: {"id": "123", "content": "Bar"}
// Once again, the platform will automatically map "content" to
// "name".
return {
result: [task],
};
},
},
});
In cases where fromKey is not sufficient and you must manually transform API results to row values and back, we recommend using helper functions with clear names to handle the convert between the different representations.
Using helper functions to transform manually
const TaskSchema = sdk.makeObjectSchema({
properties: {
id: { type: sdk.ValueType.String },
name: { type: sdk.ValueType.String, mutable: true },
},
// ...
});
pack.addSyncTable({
name: "Tasks",
schema: TaskSchema,
// ...
formula: {
// ...
execute: async function (args, context) {
let tasks = await getTasks(context);
// Each task looks like: {"id": "123", "content": "Foo"}
// Manually map the "content" field to the "name" property before returning it.
let rows = tasks.map(task => formatTaskForSchema(task))
return {
result: rows,
};
},
executeUpdate: async function (args, updates, context) {
let update = updates[0];
let row = update.newValue;
// The new value looks like: {"id": "123", "name": "Bar"}
// Manually map the "name" property back to "content" before sending it to the API.
let task = formatTaskForApi(row);
task = await updateTask(context, task);
// The final value will look like: {"id": "123", "content": "Bar"}
// Once again, manually map "content" to "name" before returning it.
row = formatTaskForSchema(task);
return {
result: [row],
};
},
},
});
function formatTaskForSchema(task) {
return {
...task,
name: task.content,
};
}
function formatTaskForApi(row) {
return {
...row,
content: row.name,
};
}
Batching updates¶
By default row updates are processed one at a time, which makes the coding simple but can impact performance when many rows are being updated at once. You can greatly improve performance by batching multiple updates into a single executeUpdate call and processing them in parallel.
The batch size can be adjusted by setting the maxUpdateBatchSize field of the sync formula. You'll also need to adjust your executeUpdate function to be able to handle multiple updates at once. Use a batch update endpoint if your API provides one, or if not make fetch requests in parallel to realize performance gains.
Selecting a batch size
A single execution of the executeUpdate function can run for at most 60 seconds, after which it will be killed and the update will fail. To allow for variability in network and server conditions it's best to set a target of 30 seconds or less for each batch. How many rows that equates to depends heavily on the API being used and the number of requests it takes to update a row, and some experimentation may be required to find an ideal size.
pack.addSyncTable({
// ...
formula: {
// ...
maxUpdateBatchSize: 10,
executeUpdate: async function (args, updates, context) {
// Create an async job for each update.
let jobs = updates.map(async update => {
let response = await context.fetcher.fetch({
// Update request details ...
});
return response.body;
});
// Wait for all of the jobs to finish .
let completed = await Promise.allSettled(jobs);
// For each update, return either the updated row or an error if the
// update failed.
let results = completed.map(job => {
if (job.status === "fulfilled") {
return job.value;
} else {
return job.reason;
}
});
return {
result: results,
};
},
},
});
When processing updates in batches be sure to return the same number of results as there were updates, in the same order. If an individual update fails, catch the exception and return it in the results array to indicate that the row update failed. Unhandled exceptions will prevent the entire batch from completing and won't give the user a clear indication of which row was the cause. See the Handling errors section below for more information.
Property options¶
Similar to parameter autocomplete, you can provide a suggested set of options for mutable properties, which will be shown to the user when they are editing a corresponding cell.
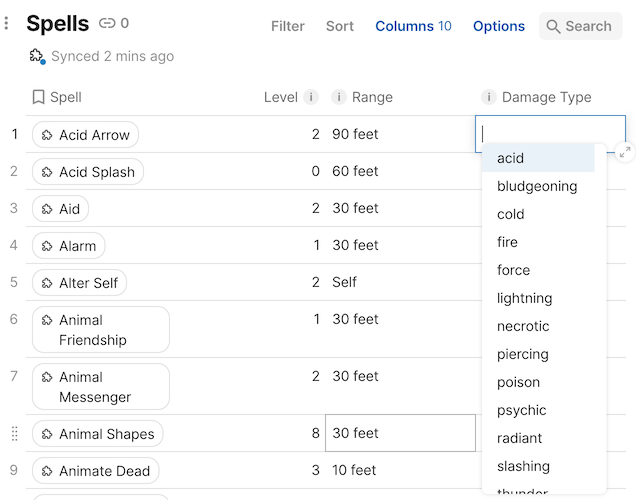
The hint SelectList or Reference is required
Suggested options is only available for properties that have the codaType set to SelectList or Reference. These will cause the property to render as a Superhuman Docs Select List or Relation column respectively.
The possible choices are defined in the options field of the property, which can be either an array of static values or a function that generates them dynamically. An options function can access the value of other properties in the row via context.propertyValues and the current search string typed by the user via context.search.
const ShirtSchema = sdk.makeObjectSchema({
properties: {
size: {
type: sdk.ValueType.String,
codaType: sdk.ValueHintType.SelectList,
mutable: true,
options: ["S", "M", "L", "XL"],
},
color: {
type: sdk.ValueType.String,
codaType: sdk.ValueHintType.SelectList,
mutable: true,
options: async function (context) {
let size = context.propertyValues.size;
let availableColors = await getColorsForSize(context, size);
return availableColors;
},
},
pattern: {
type: sdk.ValueType.String,
codaType: sdk.ValueHintType.SelectList,
mutable: true,
options: async function (context) {
let search = context.search;
let patterns = await searchPatterns(context, search);
return patterns;
},
},
},
// ...
});
In dynamic schemas¶
For sync tables with dynamic schemas, you aren't able to define the options function directly on the property itself. Instead use the special value OptionsType.Dynamic, which tells the platform to call the sync table's propertyOptions function. This is a single function that handles the option generating for all dynamic properties. It's defined directly on a dynamic sync table, or within the dynamicOptions of a regular sync table. The function can determine which property to provide options for by inspecting context.propertyName.
pack.addDynamicSyncTable({
// ...
getSchema: async function (context) {
let attributes = await getCustomAttributes(context);
for (let attr of attributes) {
properties[attr] = {
// ...
codaType: sdk.ValueHintType.SelectList,
mutable: true,
options: sdk.OptionsType.Dynamic,
}
}
// ...
},
propertyOptions: async function (context) {
let attr = context.propertyName;
let options = await getCustomAttributeOptions(context, attr);
return options;
},
});
pack.addSyncTable({
// ...
dynamicOptions: {
getSchema: async function (context) {
// ...
let attributes = await getCustomAttributes(context);
for (let attr of attributes) {
properties[attr] = {
// ...
codaType: sdk.ValueHintType.SelectList,
mutable: true,
options: sdk.OptionsType.Dynamic,
}
}
// ...
},
propertyOptions: async function (context) {
let attr = context.propertyName;
let options = await getCustomAttributeOptions(context, attr);
return options;
},
},
});
Allow new values¶
The default behavior is to only allow users to select from the set of options provided. However there are times where you may want to also allow users to create new values from within the sync table. For example, a schema property that represents a set of user-defined tags. This can be controlled using the schema field allowNewValues.
const TaskSchema = sdk.makeObjectSchema({
properties: {
// ...
tags: {
type: sdk.ValueType.Array,
items: {
type: sdk.ValueType.String,
codaType: sdk.ValueHintType.SelectList,
options: async function (context) {
let tags = await getTags(context);
return tags;
},
allowNewValues: true,
},
mutable: true,
},
},
});
The allowNewValues setting can only be enabled for String properties, as there is no way to the user to define new Object values on the fly.
Handling errors¶
When a row fails to update Superhuman Docs will show an error message attached to that row. The pending edits will be retained, so that users can adjust them and try again.
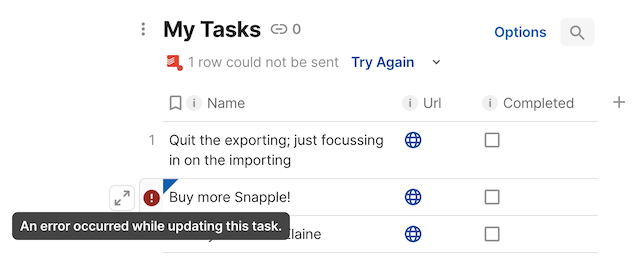
To associate an error with a row return it at the corresponding index in the result array. For tables that use single row updates (maxUpdateBatchSize == 1) if you throw a UserVisibleError it will be associated with the row automatically. In all other cases a thrown error will be treated as a failure of the entire sync and cancel any remaining row updates.
Requiring additional OAuth scopes¶
If your Pack uses OAuth authentication it may require that the user to approve additional permissions (scopes) in order to make the edits. Users can be hesitant to allow Packs to made changes to their data, so it can be useful to only request these scopes when the user begins making edits using two-way sync. This can be done by using incremental authorization, and you can learn more in the OAuth guide.