Skip to content

Operations: Coda uses operations to create a document (see for details on this technology), each of which represent a small change made to a doc, like adding a line, removing a word, or creating a table.Doc schema version: a number representing what “version” a doc is on. Versions are monotonically increasing and manually added as we add or change the way we process or store doc data and operations (i.e. , our storage , and more).Upgrades: the process of migrating docs from old to new schema versions. Docs undergo an upgrade automatically through the workflow system when a new version is enabled.
Unique identifiers: Every object has a unique identifier. If we just copied over the same identifier from the template, we’d run into ID collisions when a template is used more than once. However, we can’t simply generate new IDs blindly because we need to maintain the object dependencies defined within the template. To handle this, we create new IDs for all the new objects that are in the copied selection, and re-map all the references to these objects within the template appropriately.External interactions: In certain cases, we want to consider the doc where the template is being pasted, and modify its content using the template’s content. For example, if you’re starting with a template from a blank page, you likely want to replace the blank page you’re on with the template. In this case, we offer contracts for changing the references inside the template, catered to the specific context at the time of paste. In the example above, we offer a mechanism to pass through information on paste to replace the active page in-place rather than creating a new page.
Different doc versions: Docs are associated with different schema versions as mentioned above and level up via upgrades. However, because upgrades happen asynchronously and can run into issues for large docs, we could have a template that is a different version from the doc a user wants to use it in. How do we handle this, especially when a newer version could have logic that doesn’t exist in the older version?Fast paste: Copy and pasting should feel fast because our makers want to create at the speed of thought. How do we make this feel performant when templates could include hundreds of operations behind the scenes?

 Optimistic computation: We automatically compute and save the copy information, the operations and the additional metadata we need for inserting a template, whenever a template is changed. Doing so ensures that the updated template is available as soon as we have processed the changes to minimize the work needed at paste time.Data store for quick access: When we fetch templates for use within a doc, we avoid sending the copy information over the network because each one could contain hundreds of KBs or even a few MBs of data. Instead, we upload this computed information to a simple, low-latency storage layer and lazily load the info from this storage layer as soon as the user indicates they may want to use a template (for example, as soon as you start dragging it) and cache it in the browser for repeated usage. This process ensures a smooth, fast insertion even for larger templates.
Optimistic computation: We automatically compute and save the copy information, the operations and the additional metadata we need for inserting a template, whenever a template is changed. Doing so ensures that the updated template is available as soon as we have processed the changes to minimize the work needed at paste time.Data store for quick access: When we fetch templates for use within a doc, we avoid sending the copy information over the network because each one could contain hundreds of KBs or even a few MBs of data. Instead, we upload this computed information to a simple, low-latency storage layer and lazily load the info from this storage layer as soon as the user indicates they may want to use a template (for example, as soon as you start dragging it) and cache it in the browser for repeated usage. This process ensures a smooth, fast insertion even for larger templates.
Jeremy Olson, Steve Won, Jasmine Jones, Andrew Hsu, Oleg Vaskevich, and Sohan Murthy for elegant framing, design details, iterative engineering, and data magic.Erin Dame, Elaine Song, and more for the customer outreach, launch strategy, and copy wizardry.John Scrugham, Toni Watt, and others on our customer support and customer success teams for handling all the questions and ensuring a smooth rollout in our largest organizations.Special thanks to Chris Eck, Erin, Oleg, Elaine, and Bala Neerumalla for reviewing and edits.
Share
Explore
Rituals at Scale: How we remixed templates
The details behind our custom templates system.

A few weeks ago, we , enabling teams to create and easily reuse their own workflows. In this post, I’ll dive into the principles behind creating this feature and challenges we encountered to show how we tackle hard problems and balance engineering and product concerns at Coda to create an empowering and future-proof experience for users.
Platform for creation
In any platform for creation, the biggest hurdle is knowing where to start. When the realm of possibility is limitless, the barrier to entry is high because of how many different directions you could go. It’s choice overload.
GitHub is a successful example in this scenario. Sharing code and collaborating together were already part of the standard git versioning system, but GitHub introduced a new concept—forking code paths—which made it dramatically easier to kick-start an idea by building off of existing systems. As a result, the number of new creators in the ecosystem multiplied with new builders riffing off each other’s creations. Forking enabled the remixing of software creations.
Non-technical ritual platform
Coda is a new doc that brings words, data, and teams together through flexible building blocks that help create content, store and sync data, and build custom workflows. We’ve seen people use Coda to make everything from OKR trackers to inventory management systems to recipe exchanges and more.
More specifically, Coda provides a platform for creating software using documents instead of traditional software languages—a surface that emphasizes the concrete, common-sense concepts in solving a problem with data rather than forcing translation through specific programming language concepts. We’re building a new universal “programming” language, like a data-empowered Excel, starting from a familiar surface, the document, so that non-technical makers can create their own software and shape the tools they work with to solve their problems and fit their specific needs, rather than the other way around. We’re enabling non-technical people to create their own tools and templatize the processes they use every day—their rituals.
Regardless of how approachable we make Coda, working with data and software is inherently hard, because there are fundamental data concepts that are difficult to understand. How can we make it easier for people to familiarize these concepts while tackling their problems and playing with ideas? In other words, how can we lower the barrier to entry for actualizing ideas in Coda?
Similar to how GitHub enabled sharing and collaborating code, we in order to enable sharing rituals, but we didn’t have a first-class concept to enable remixing until custom templates.
The components of a template
The biggest technical challenge we encountered while developing custom templates was crafting an approachable and frictionless experience while handling the technical complexities elegantly. We focused on handling complexities behind the scenes, so that makers can focus on creating at the speed of thought and sharing their rituals.
Before we go deeper, here are some Coda-specific engineering terms I’ll re-use throughout the post.
Up-leveled copy and paste
We’ve always had the capability to copy documents. And we also had a small set of Coda-curated drag-and-drop templates, essentially shortcuts for copying pieces of Coda creations and pasting them into your current context. But we’ve never enabled users to create their own custom templates that integrated seamlessly into their existing flows and scaled to their desires.

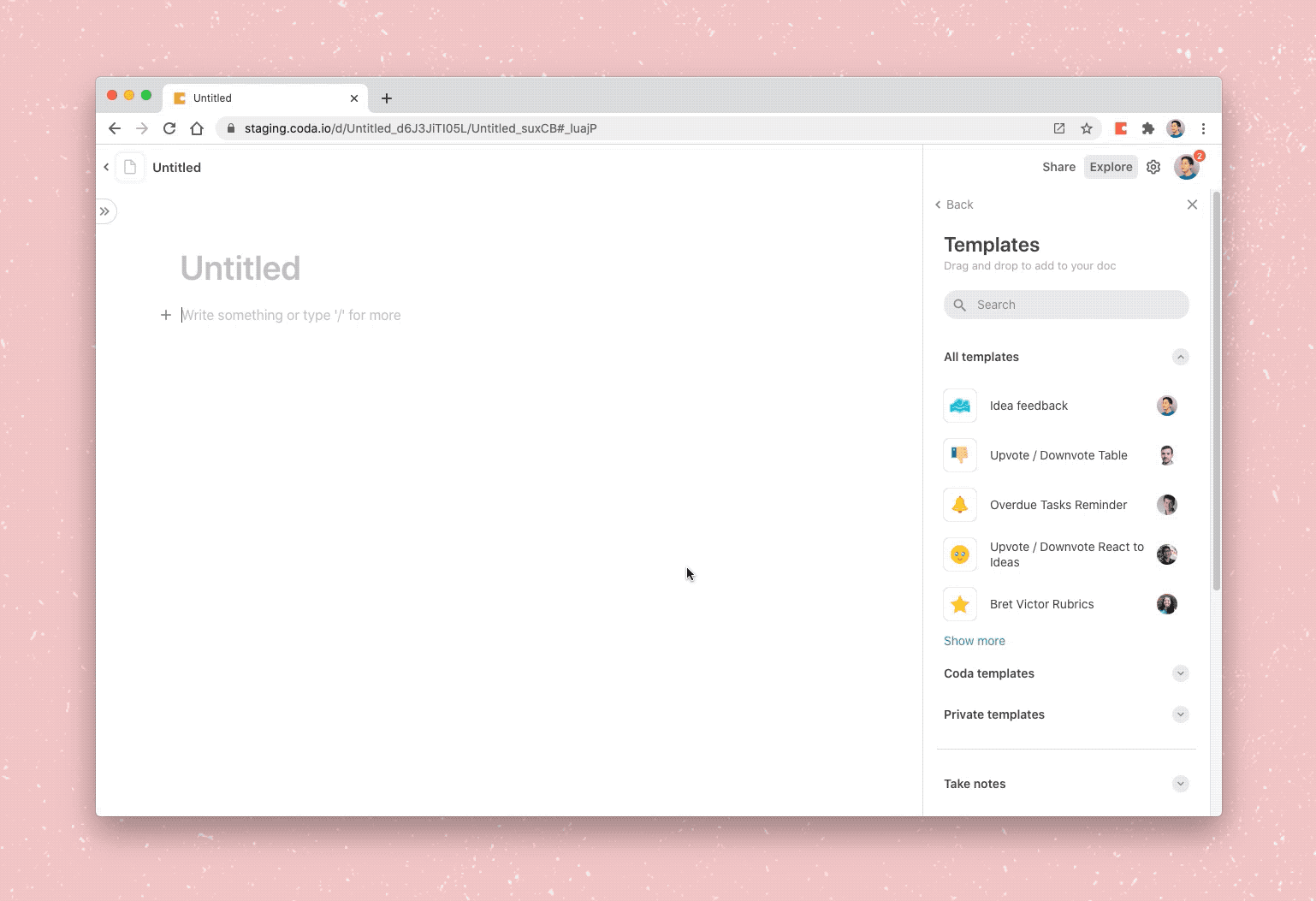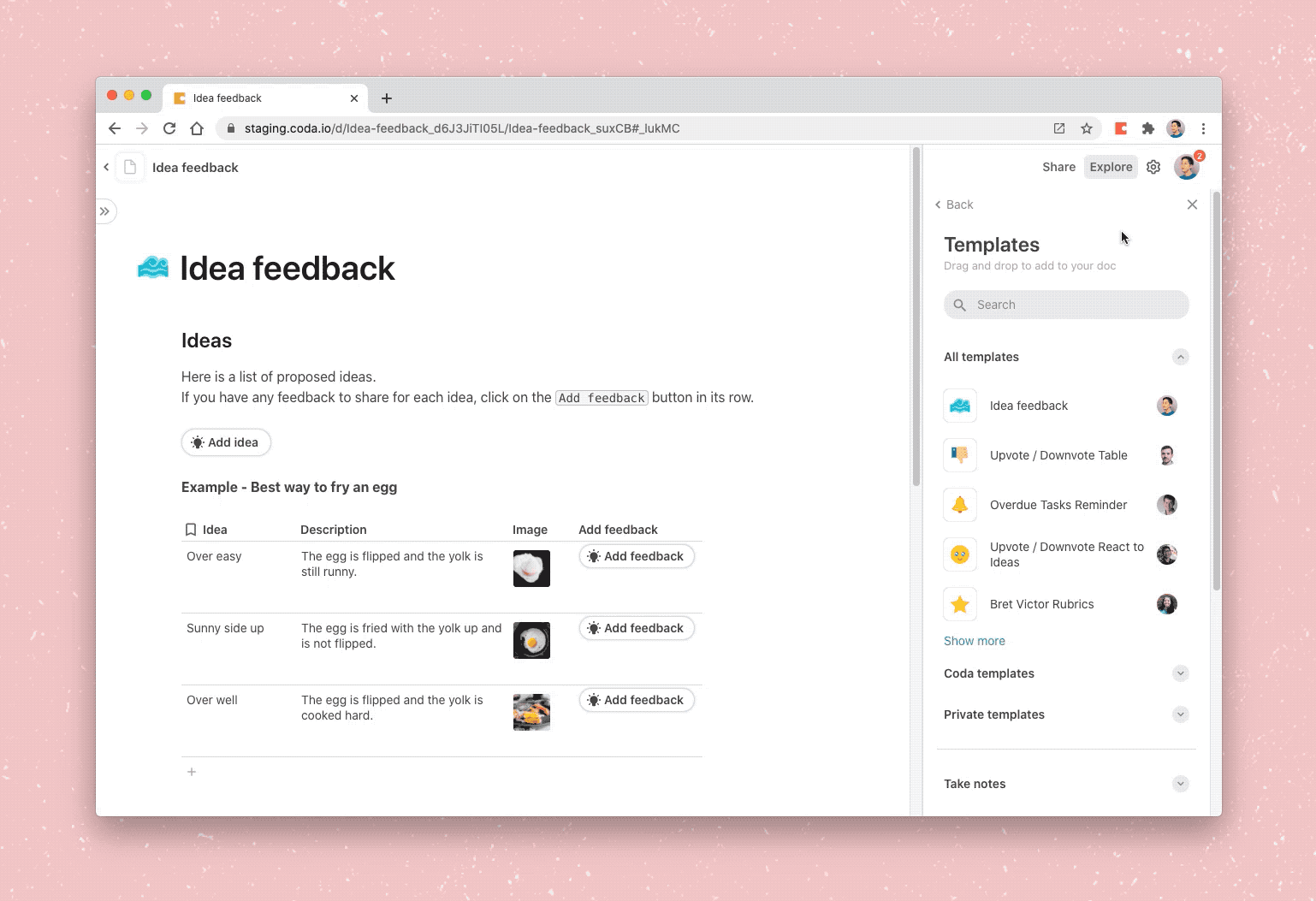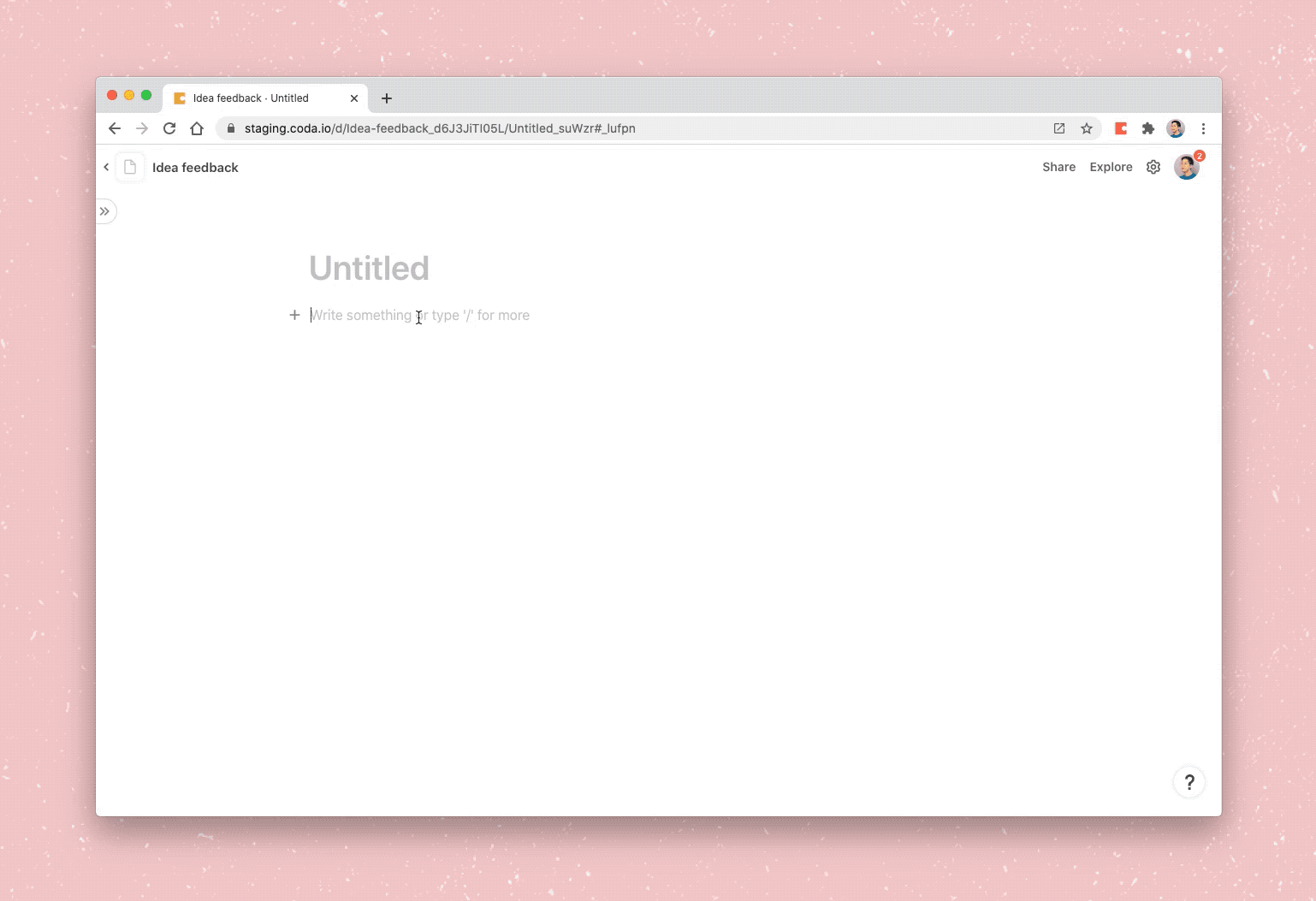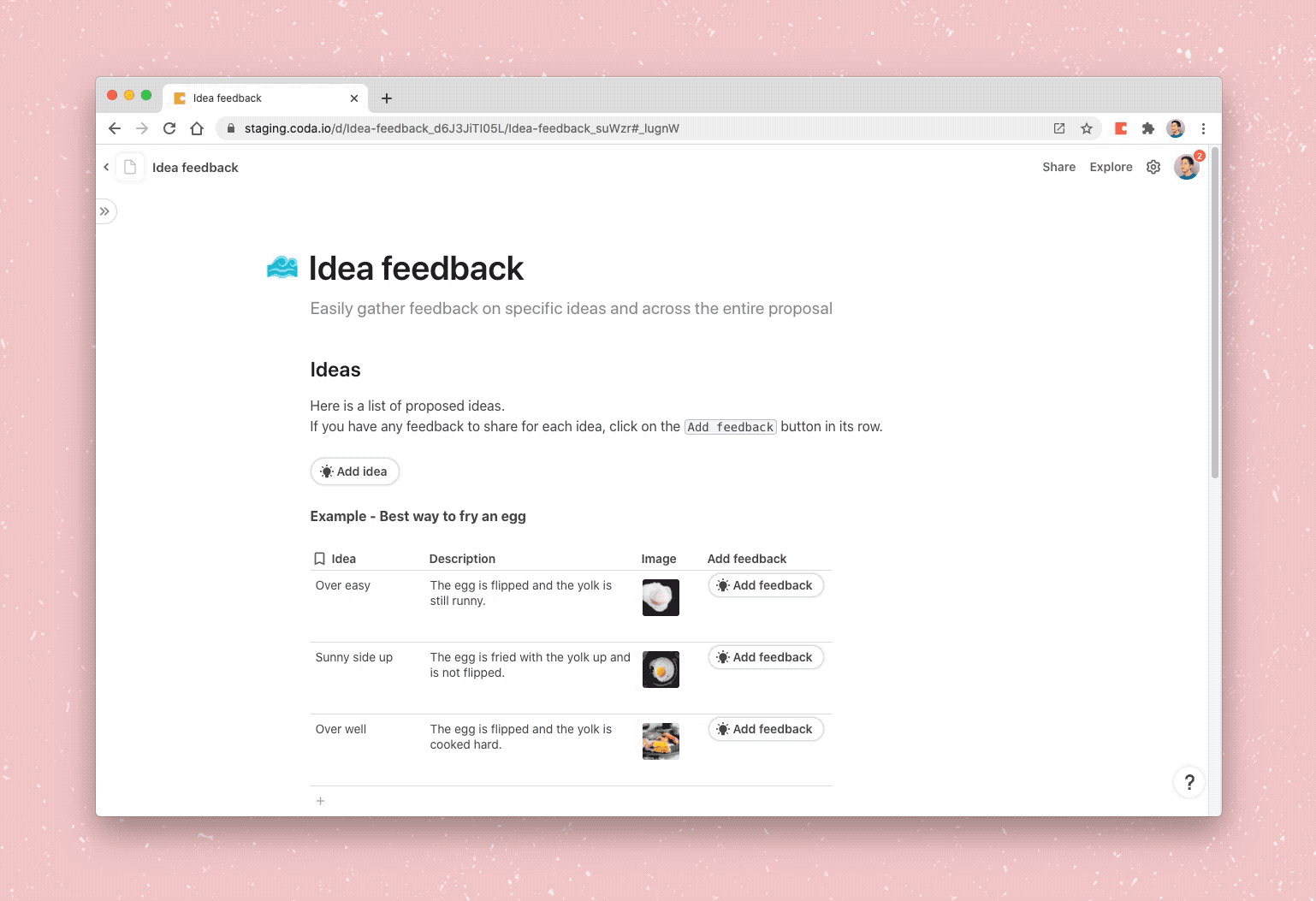
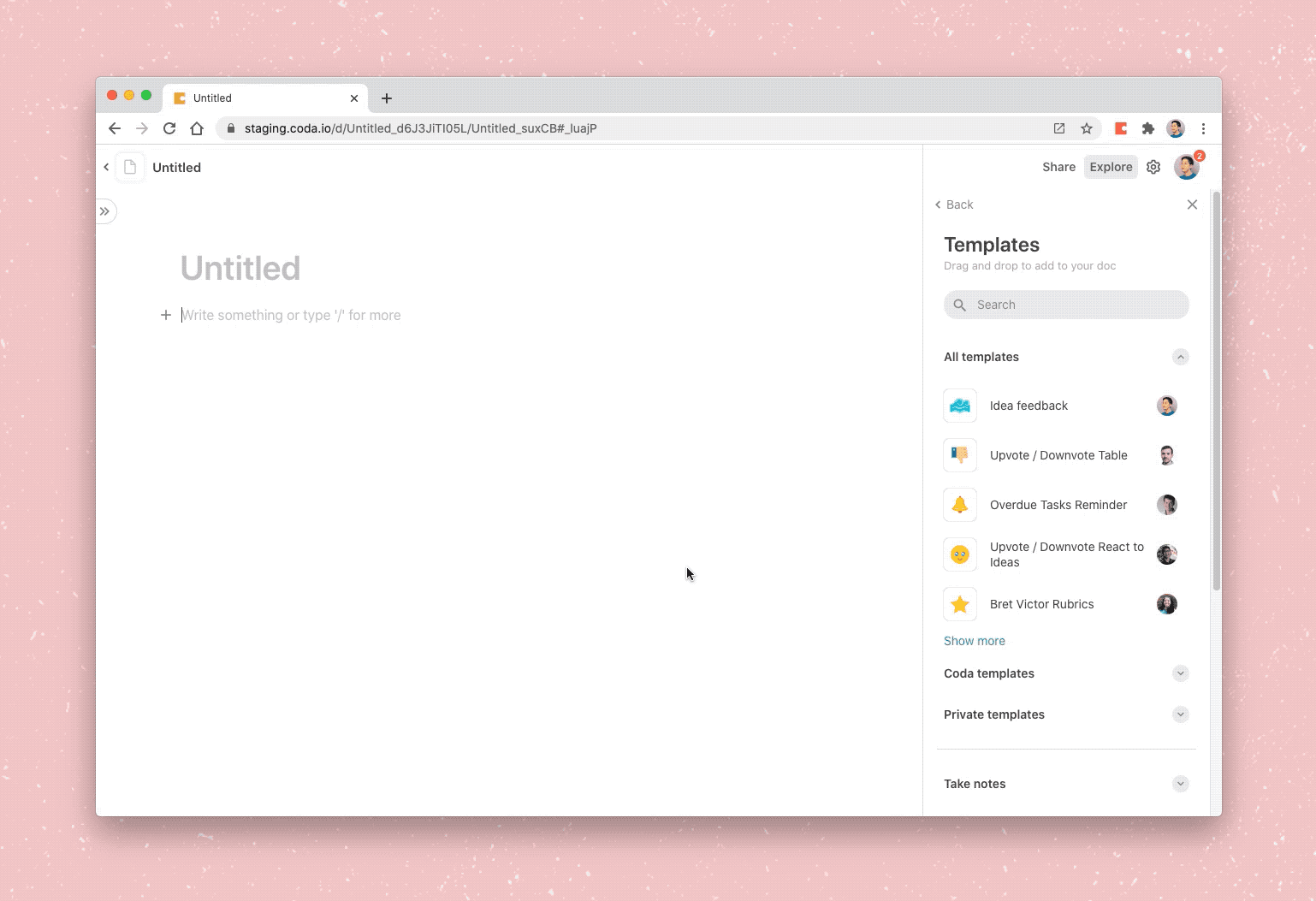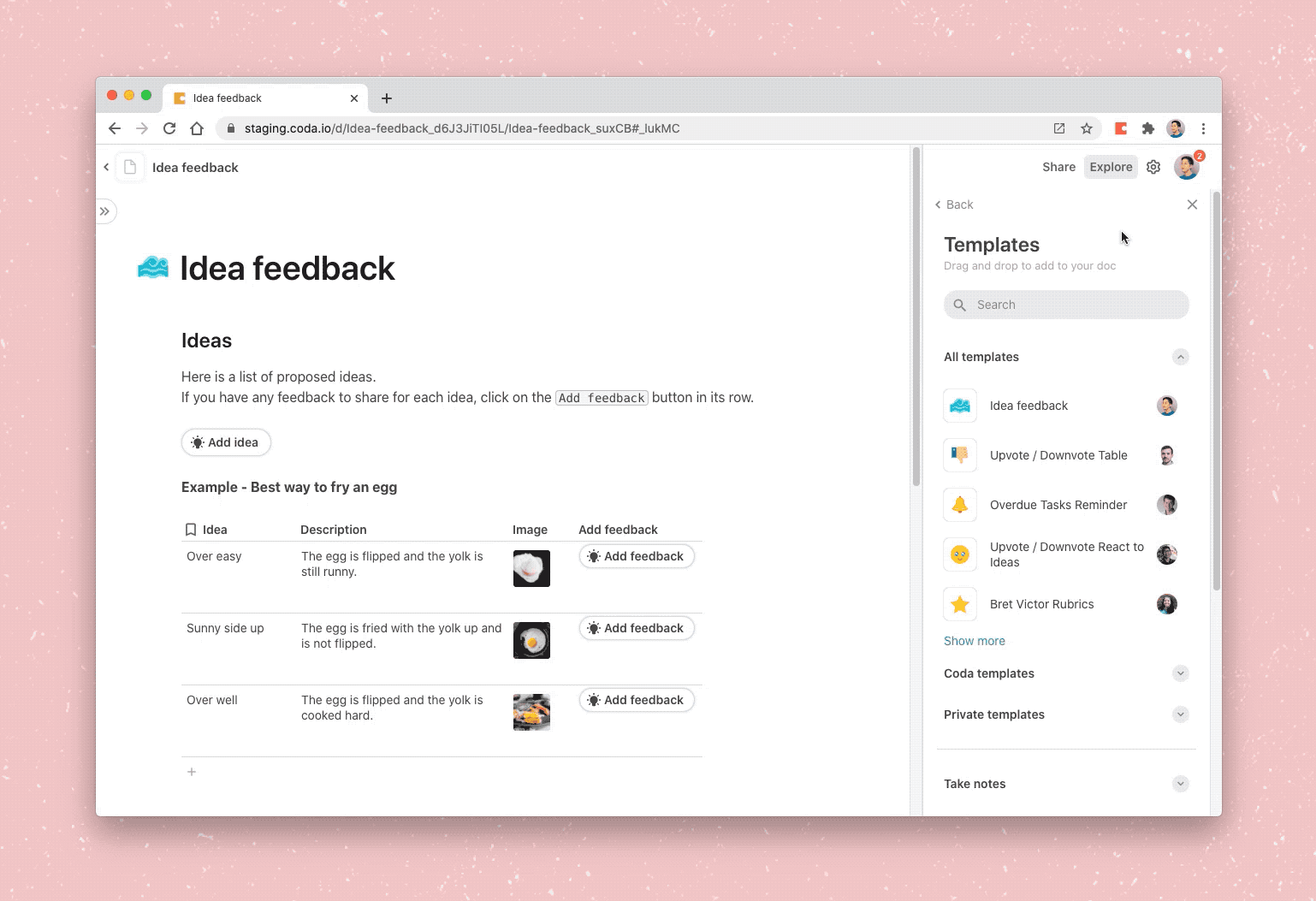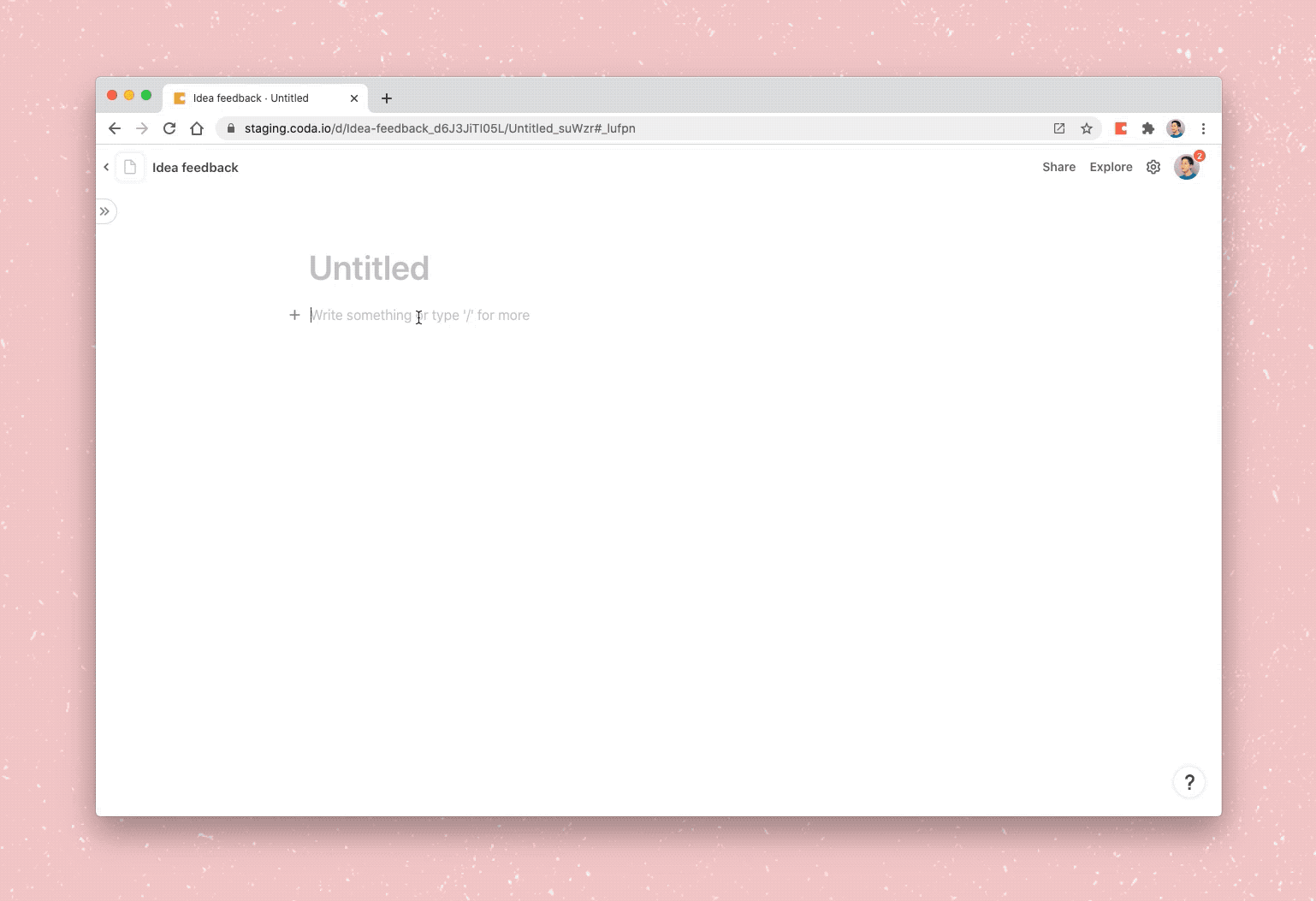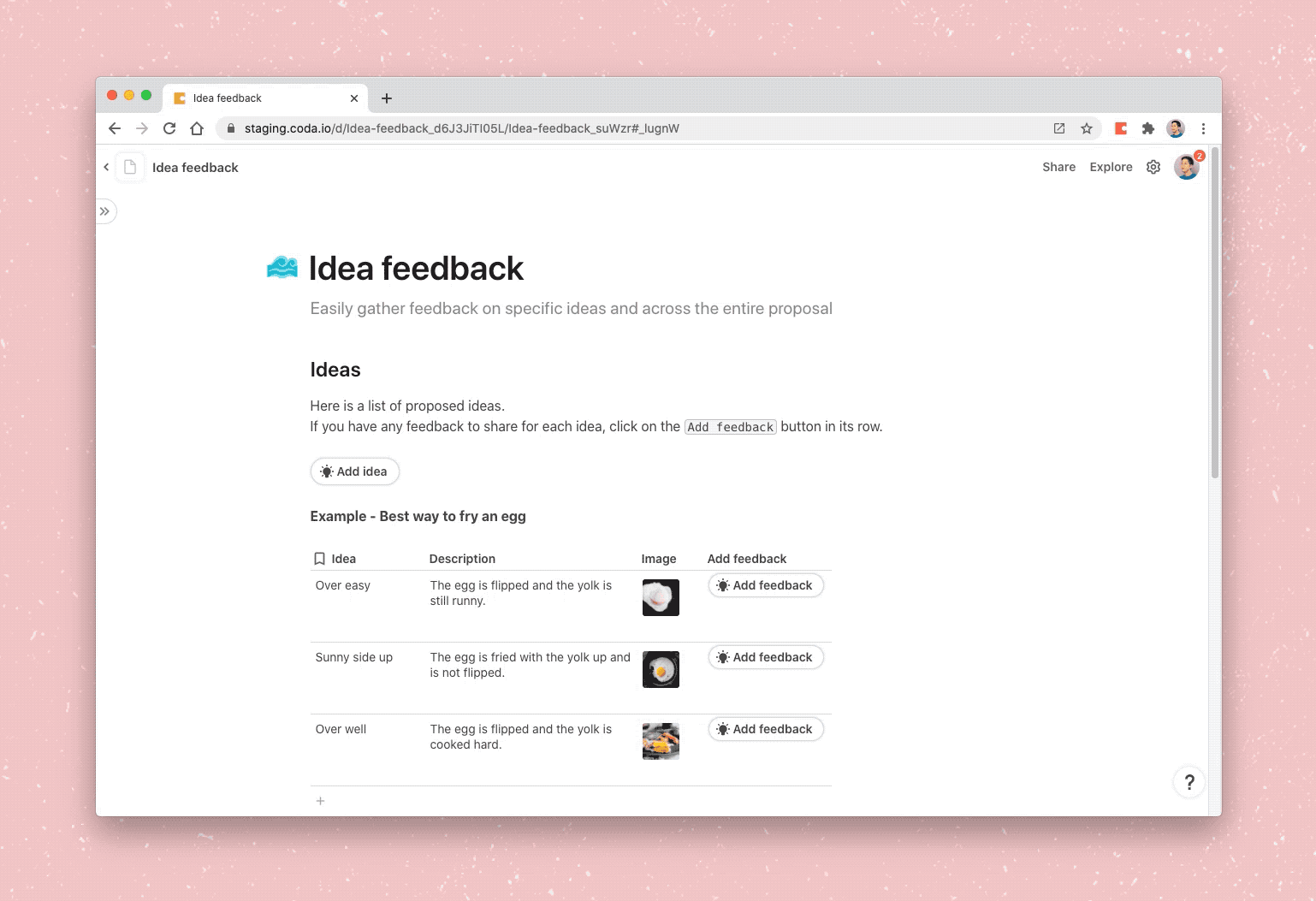
Drag and drop templates into your doc or type /idea
While copying and pasting is pretty simple for plain text, copying interacting building blocks presents a challenge because content in Coda is represented as a series of operations instead of the static content itself. As a result, in order to recreate a piece of content in a doc, we need to apply all of the composite operations, the series of actions that compose the content.
With that foundation, the steps to recreate selections of docs are 1) generate the set of operations that composes that selection (copy) and 2) apply those operations to the doc when you use a template (paste). While this sounds simple in theory, there’s several details to ensure everything works as expected.
Copy: Deriving operations
In order to derive the operations used for copying, we traverse the doc (or just a selected portion) and produce the operations necessary to recreate each piece. For each type of object (pages, buttons, tables, etc.), we encode logic for deriving the composite operations.
One complication we have to handle while deriving the operations is dependency hierarchy. Unlike plain text, objects in Coda can be dependent on one another. For example, a page might contain a table which has a formula for a column. Because of this, the order in which we apply the operations is crucial to a correct end-result (trying to create that table without the page would break!). To properly handle ordering, as we traverse the doc, we build up a dependency tree, which we use to decide the order of operations when we go to paste.

simple example of dependencies: a page with a table and a formula
Paste: Applying operations
Even though we’ve done a lot of legwork deriving all the operations up front, we still have to account for some issues at the time of paste:

Using a template on an empty page replaces the page data, like the cover image, subtitle, and icon.
With these resolved, we can apply all the operations included in the copy information for a template in the order specified by the dependency mapping, and voilà: a custom template.
Scaling access: Document versioning and updates
We’ve covered a high-level view of the end-to-end flow required to create and use a template in your doc and some of the complications it involves. One critical piece that we haven’t addressed in this whole flow is making it scale to thousands of teams.
There are few difficulties that arise with templates due to how powerful Coda is and our capacity for adding new building blocks:
Doc versioning
Because new versions of documents can introduce new operations or change the logic or structure of existing operations, the actual copy-and-paste logic can be different between a template and a doc that are on different versions. For example, it isn’t possible to use templates with new operations inside documents on old schema versions because that doc wouldn’t know how to interpret the new operations. The implication is that we need to enable our drag-and-drop templates to service as many different document versions at once as possible.
idea
reaction
custom
templates
remixing!
There are no rows in this table
Reactions changed doc logic by adding a new column type
To address this, we maintain a mapping that represents whether a given schema version introduces externalities that could affect how operations are created or applied, so that we can search across a range of compatible versions for a given document, instead of gating on the exact version. We also maintain the copy information for each schema version of a template. So, for an outdated doc, you’ll be able to use an older version of a new template if we had saved it previously. There’s more optimization we could do here in the future by specifying the exact operations that have been affected or introduced and gating templates only if they use said operations.
Fast paste
Because templates can contain hundreds of operations, not to mention the additional metadata we need to compute to properly handle the problems on paste outlined above, we’ve made optimizations to help make this hot path feel as intuitive and fast as copying-and-pasting text in any other app:
The second insertion of the same template is even faster because of the cache.
Templates for everyone
Another big question we wrestled with at the beginning of this project was how to make custom templates approachable and understandable for anyone, not just experienced Coda makers—to encourage remixing their repeated workflows. We bounced between different iterations along the scale of making it feel exactly like a document and making it feel like its own distinct object. Where we landed is a hybrid model that preserves all of the core parts of the document while simplifying the surrounding experience: how you share, manage, and discover templates.
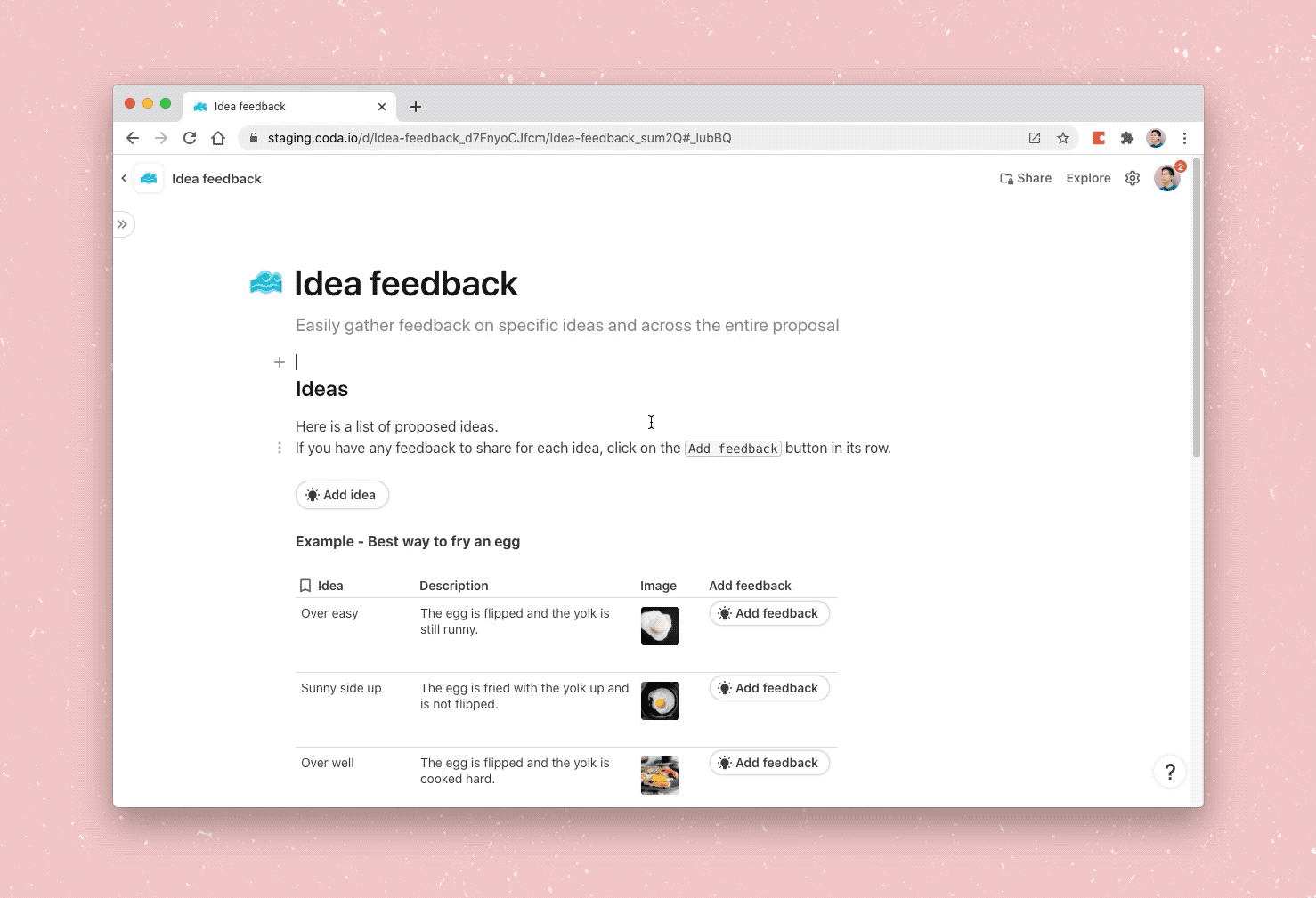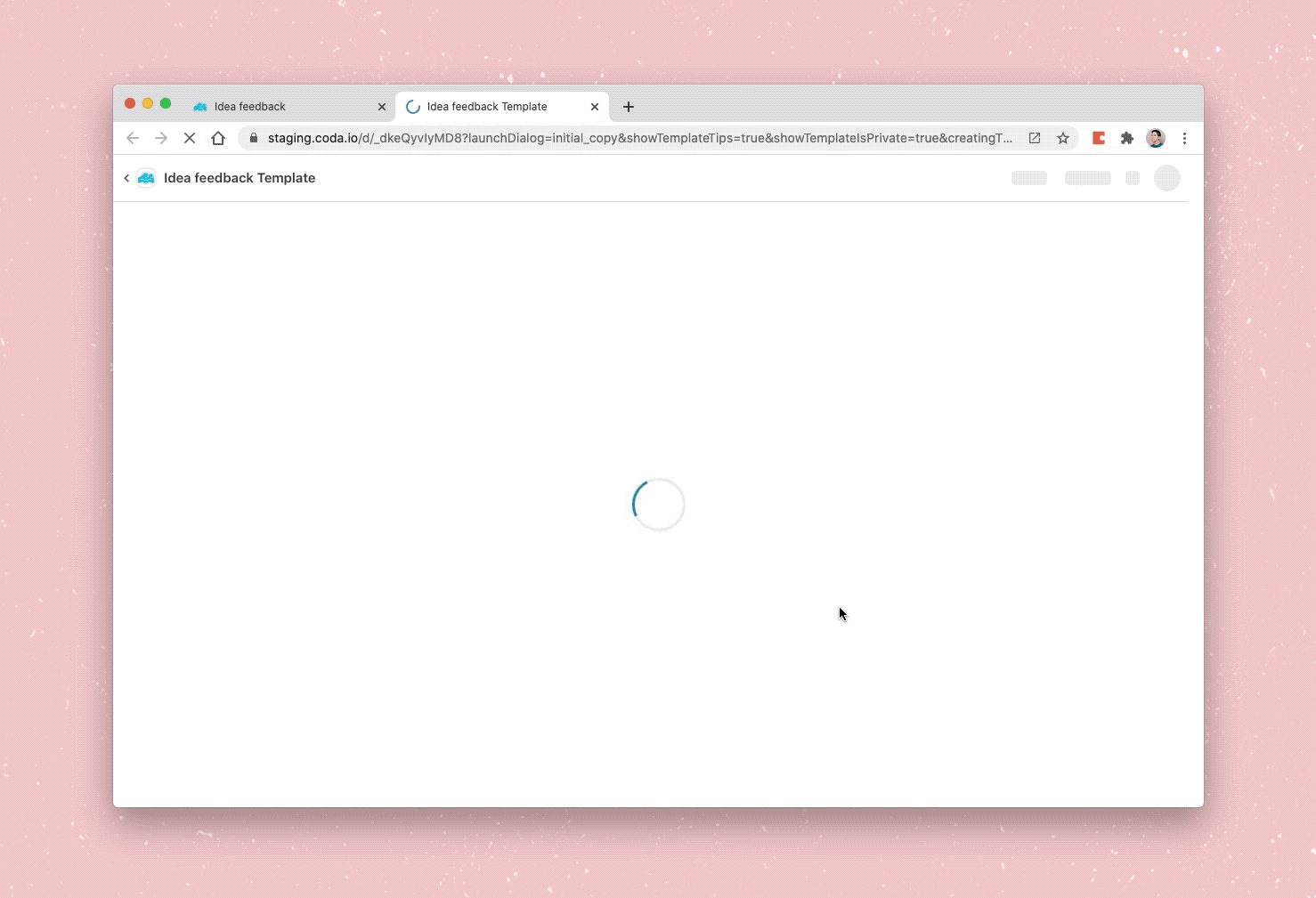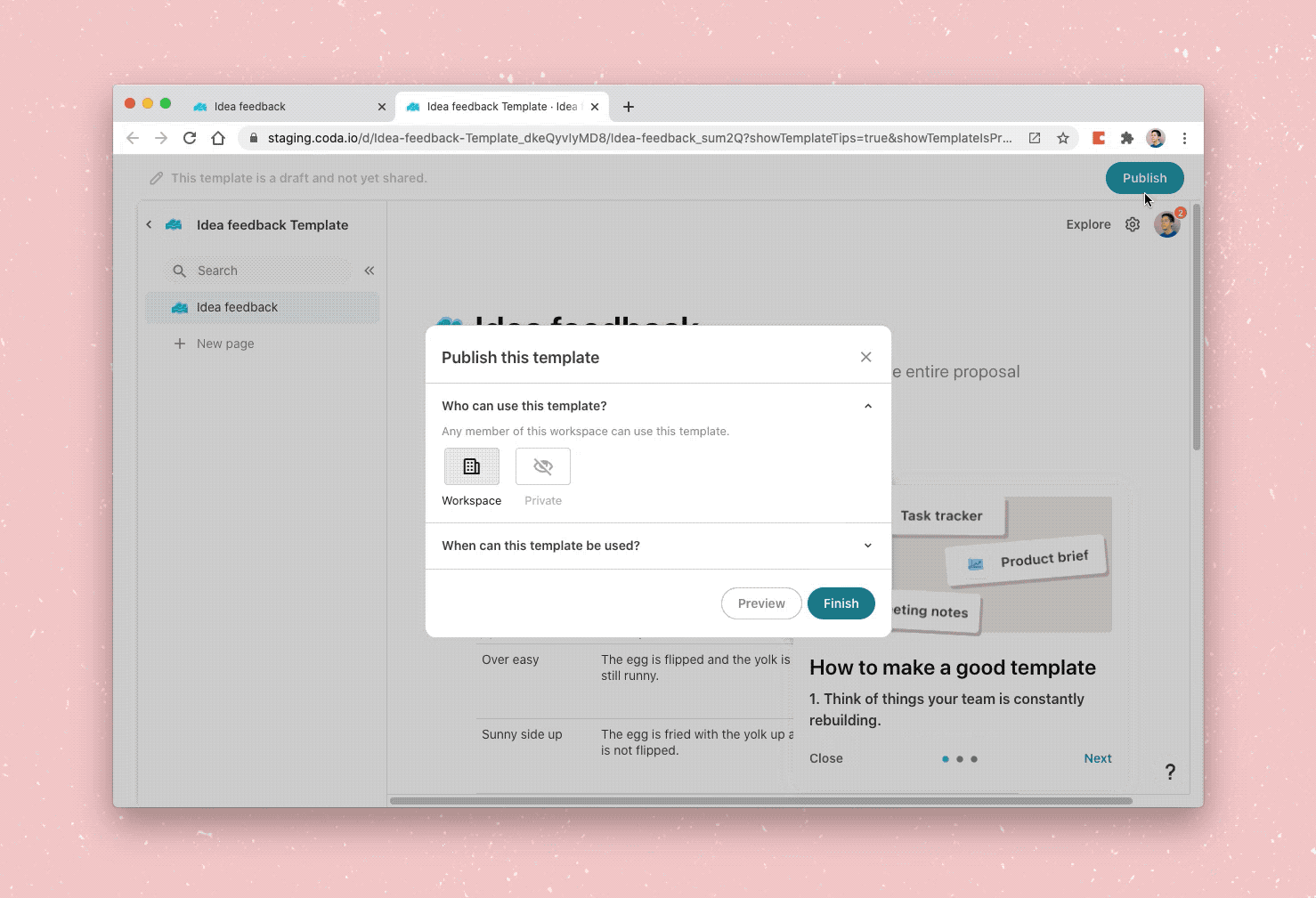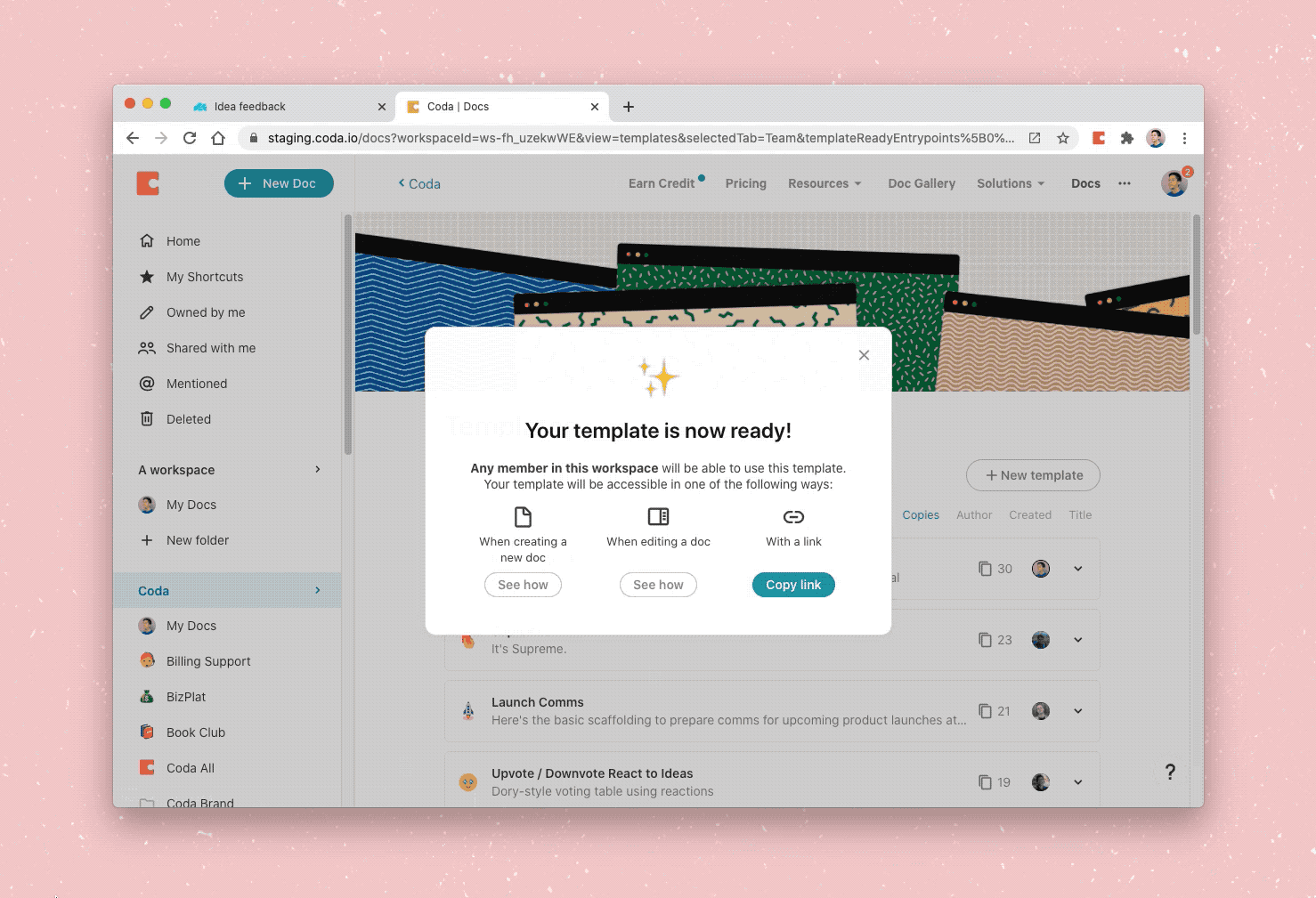
The full creation process for a template.
WIP vs. Done
One of the biggest points of conflict in the mental model for a template versus a normal document is that templates have a much greater sense of being “done” whereas documents are often living pieces of information that are continuously changed. To address this, we added a “draft” state for template, with an explicit action to publish to make it available for use. This distinction creates a simpler and clearer call to action and flow for creating a template, allowing users to start and work on a template over time without worrying about leaking an unfinished template.

Jump off an existing doc for a new template and stay safe knowing it’s unavailable until you publish it.
Easy access
While not having access to docs can be easily resolved by requesting access when you open the link, having initial access to templates is much more important because access determines whether they appear in the crucial entry points for creating docs. To resolve this, we made the sharing setting as simple as possible by giving users a binary choice between “Private” (for you only) and “Workspace” (available for everyone in the workspace), with advanced settings to manipulate more granular access. An additional benefit of this choice is nudging users to open up their template to their entire team to get use out of rather than only sharing to a select group of people, which further encourages this dynamic of remixing.

In addition to inside a doc, you have templates at your fingertips when creating a new doc.
Simple sharing
Knowing that a core part of templates is to share with your team and remix each other’s creations, we wanted to really encourage sharing templates. To encourage sharing the template for use and distinguish it from sharing a doc for editing, we added a preview link for template creators to share directly to people who might be interested in using the template, which provides an easy shortcut to play with the template and make a game-time decision on whether it fits their particular use case. We also provide this preview everywhere you can insert a template to help you know what you’re getting before you commit.

An easy way to check out and share your template.
Make it fun!
Lastly, we tried to provide as much context within the document to point the user towards creating a good template and making it fun to share with friends, through the tips provided when creating a new template, the template chrome that orients users to the draft/publish flow, and the celebratory modal we pop when a template is published. This flow works to educate users on how they can create templates that work for their team and remind them to think of designing the doc for others to use rather than a means to an end.

🎉 Your template is ready for your team 🎉
Remixing forward
After many months and iterating on feedback from our gracious beta testers, the hard work from many Codans across teams culminated in . We’ve already seen it used for everything from an to to a to hang out in. We hope that this is one of the first steps in establishing a flexible platform for creating, sharing, and remixing different capabilities in Coda and that this feature supports a greater capacity for makers to create at the speed of thought, so that they can focus on building their ideas more than the process that supports their inception.
We’re so excited to see what templates y’all will make and remix!
Acknowledgments
This feature and post wouldn’t have been possible without the awesome team that supported all aspects of this effort. Thank you to:
👋 I’m , an engineer here at Coda. Custom templates are a feature I’ve always wanted for myself, so I’m grateful I had a role in bringing this feature to life! This project was especially fun to work on end-to-end because it involved lots of hard product and engineering problems and a green field to iterate towards a large vision, which are my favorite kinds of problems to tackle and bring to life. If this is the kind of work that gets you excited too, we’re ;) Feel free to / me if you’d like to learn more and if you like this, you may like my , or subscribe for updates below.
A few of the 25,000+ teams that 🏃♀️ on Coda.

Coda is an all-in-one doc for your team’s unique processes — the rituals that help you succeed. Teams that use Coda get rid of hundreds of documents, spreadsheets, and even bespoke apps, to work quickly and clearly in one place. This template is a Coda doc. Click around to explore.
Find out how to Coda-fy your rituals.
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.