Skip to content
Everyone’s grumbling about software quality.Designers don’t feel like the product is polished enough—after all, their work is front and center. “Low quality” often becomes “poorly designed” through no fault of theirs.Engineering’s unhappy—they have dealt with a constant slew of ever-changing specs, people changing their minds about interactions and details at the last minute, and a constant pressure for feature driven development instead of taking the time to do things right.Product Management thinks the quality is terrible, and to make matters worse, everyone is moving too slowly.
Correctness. Does the software behave as it was intended to? Does it solve the problem (at a detailed level) that it was meant to solve? E.g., a user tries to upload a video to YouTube using the app. They press the upload button, and nothing happens.Performance. Is the app fast enough? Typical performance problems include app start performance (cold and warm start), data loading performance for key interactions (loading the home page, loading the profile page), interaction performance (scroll speed, animation speed). E.g., Google has famously invested much energy in speeding up Search because latency matters—a decrease of 400ms caused a 0.2-0.6% drop in searches, which compounded over time (users in the slow variants used Google less immediately, and even less over time).Reliability. Does the app reliably accomplish its purpose? App crashes are an egregious example, especially on diverse platforms like Android. Another example: upload failures when trying to post photos or videos. Reliability issues are important because they cause a drag on retention as users churn off the app in frustration.Craft. Do all the tiny details add up to create a genuinely polished experience? These bugs are rarely the most important one to fix or “launch blockers,” but they are essential to get right if you want the product as a whole to feel perfect. Want to find out how good your design craft eyes are? .
Priority 0. Look at this NOW. This priority should typically be tied together with an on-call rotation so that someone gets alerted. Services going down, significant parts of functionality going unavailable, major security problems—these sorts of things should result in a P0 bug. P0 bugs should be rare enough to warrant a formal review process around what caused the problem, its discovery, fixes applied, and lessons learned.Priority 1. Fix within 24 hours. Examples include significant flaws in the product, bugs that affect a subset of the user base, bugs that impact the brand in a significant way.Priority 2. Fix within a week. Minor problem, but it would be good to get fixed before then next major release of the feature goes out.Priority 3. Fix within the next sprint (typically 2 weeks, but as long as a month).Priority 4. Catchall priority for things that should go into the next sprint. Expect these bugs never to be looked at unless they get upgraded to P2s. Different teams prefer to have these lying around because they are a documentation of everything wrong or delete them because they are mostly useless.
P0: No outstanding bugs. If you have a P0 bug, stop all feature development until you have fixed that bug.P1: A small number, say 0.25 / engineer.P2: You should expect a fair number of these bugs and give teams room to get these under control - say 1 / engineer.P3: A larger number. 5 / engineer.P4: Unbounded.
 Software Quality, Bugs, and SLAs
Software Quality, Bugs, and SLAs
A guide on how to keep your engineering team on track by a former Director of Engineering and Product Management at Facebook.

Your app feels buggy. There are lots of small code quality issues, and it crashes now and then. The engineering team is buried in bugs; they don’t know which ones to address first. What do you do? How do you get the product feeling great, the engineering team feeling productive and proud of delivering a high-quality product, and pump out features while keeping the bugs down?
Software application development is an inexact science. We write code and build software products full of defects. If we are lucky, we are aware of the defects and can catch them before they go to our customers. Engineering teams often feel they are in an epic struggle to build the perfect product while dealing with ever-changing requirements and product specs, framework changes, and evolving infrastructure.
An engineering team’s objective is to make forward progress on building their product while keeping their product quality “good enough.” The definition of “good enough” is defined by company values and the context surrounding the product. A hardware device with a slow update cycle has a significantly higher bar than an iPhone app that can be updated quickly. Different companies have different quality bars as well—Instagram pays a significant amount of attention to small visual design problems, creating in a product that feels extremely polished and well crafted. This variability in the definition of a quality bar, from company to company or product to product, can be overwhelming. People give up, resulting in the complete lack of a defined bar, or a quality bar where every software bug is a blocker.
A typical scenario goes something like this:
Typical responses to this include bug bashes, quality weeks, bug triage meetings every day, and burndown lists of launch-blocking bugs. Carried out over sufficient lengths of time, these lead to morale issues, finger-pointing, burnout, attrition, and, importantly, no sustained quality improvement. The herculean effort might result in the feature getting out, but you know we’re just going to be here again in four weeks.
Below, I lay out a pragmatic framework for dealing with software quality issues. While the framework isn't detailed enough to simply copy-paste it into action, we can decompose a gnarly problem into different measurable axes, forge a path toward maintaining a high quality standard, and pay down long term bug debt.
1. Defining Quality
There is much academic literature on this subject, generalized to everything that software engineering covers. For engineering teams building modern apps and consumer-facing software, I tend to use the following axes:
At this point, you’re thinking: hang on. What about engineering architecture, testability, efficiency, and reusability? These aspects are critical to software development and can slow down engineering development, or contribute to fragility and a game of bug whack-a-mole. Isn’t it important to document those and burn those down as well?
These are essential engineering projects that good teams work on at any given time. However, they do not directly manifest themselves as user-facing problems. Separating the two, treating “quality” as strictly user or customer-facing problems helps engineering teams speak the same language as their product and design counterparts and bring pure engineering problems in-house. Longer-term infrastructure improvements can be decomposed and folded into the same priority system; it is merely out of scope for this conversation.
2. Prioritization
Most engineering teams have a prioritization framework that provides an estimate on how quickly they a bug is addressed. A defect might take a long time to get fixed, even though it got looked at immediately, usually because it is a gnarly, hard to reproduce the problem. Or the engineering team is so overloaded digging themselves out of a debt hole that things are just going to take time.
A priority framework provides common terminology and an agreement about how urgently the team needs to look at a bug. In other words, it is an SLA that the engineering team agrees to uphold. Here is my general priority framework:
A meaningful and functional SLA process requires commitment and discipline from the engineering team to uphold their side of the bargain and look at (and fix) bugs in the allotted time. It also requires the product, design, QA, and other teams to not abuse the system by needlessly escalating every bug or arguing with the eng team about the priority. When this trust breaks down, the system goes from being a helpful framework to something that makes people feel trapped.
3. Continuous Improvement
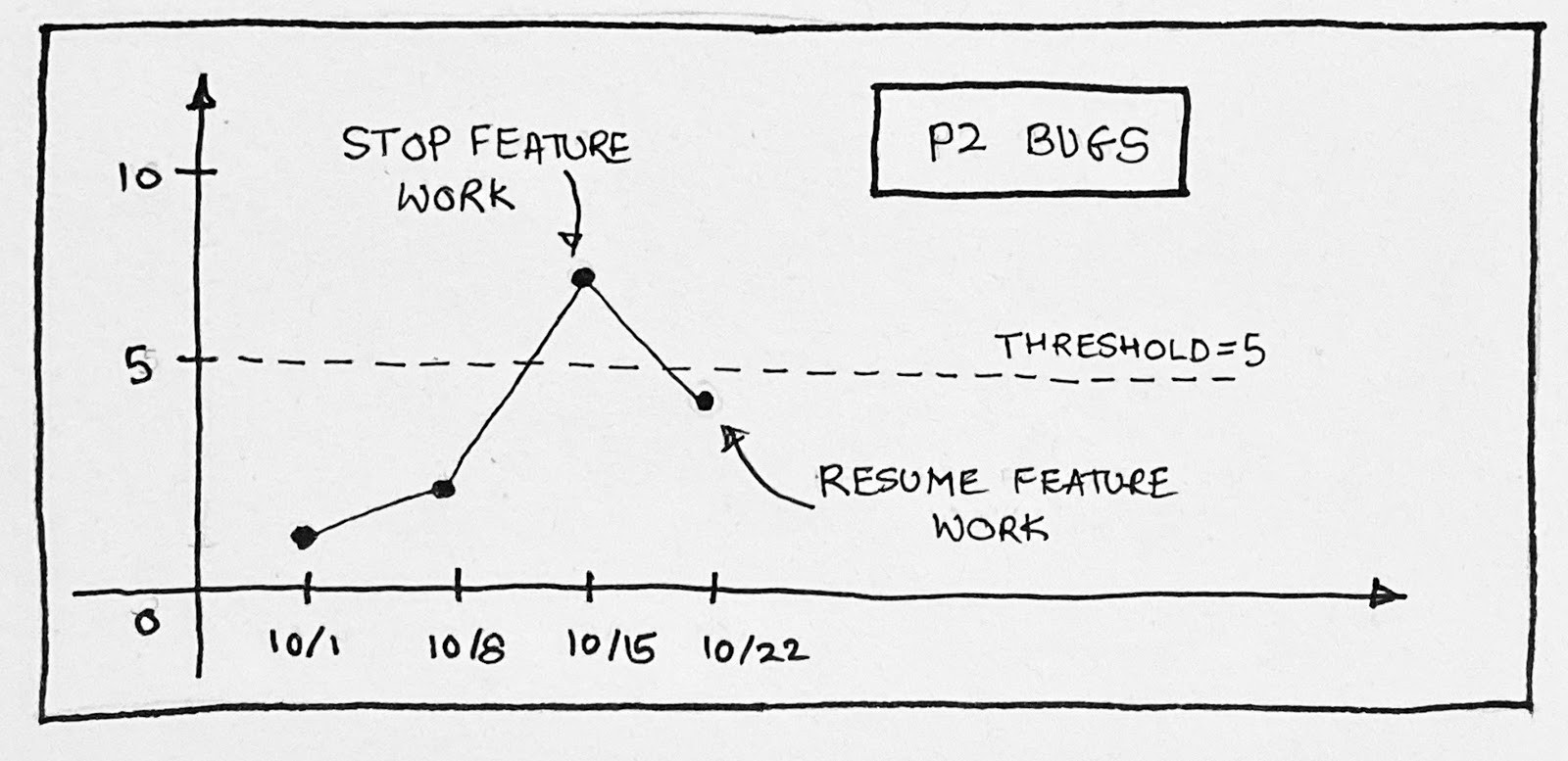
There is a constant tension between pushing features and improving quality. Determining when to pull the “emergency stop” brakes and get quality under control is hard to do. In the ideal world, all bugs would be perfectly prioritized, and there would be no SLA violating bugs. Good teams can reach and maintain this state. However, when a team is just starting to institute this process, the bug load can seem daunting. One approach to pay down the debt is to institute a process that limits the number of bugs that are allowed to be out of SLA to allow the team to continue to do feature development. Over time, this overage number ratchets down, going to zero over the space of a few months (or sooner depending on the team and how much bug debt they have).
The key metric to look at is “Number of SLA violating bugs in a priority bucket.”
Set a realistic target of how many SLA violations you’re willing to allow. As an example:
At this point, the team can take an actual goal to stay under the max-violations limit and continue to ratchet things down over time.
4. Accountability
Processes are tools and, like any tools, are subject to abuse. They are not meant to prevent adversarial plays—if the process becomes too cumbersome, teams stop adopting it, and it fails to achieve its purpose. A fundamental assumption of a Bug SLA process is that there is broad adoption and accountability at the highest level.
At Facebook, when we instituted such a process, there was a bi-weekly meeting where all the senior eng managers would sit in a room with the head of the Facebook app, with the person running the SLA process (TPM) presenting who was doing well and who wasn’t. There was no yelling or blame; it was a rather simple “What’s going on, and how can we help?” conversation. But you did not want to be the person answering that question. The accountability was a social construct, and it worked exceedingly well.
Making sure that the leadership is bought in, at the highest level, as well as peer functions (product and design), is essential to making the process a success.
Conclusion
A systematic approach to product quality can help produce a product that is a joy to use—a product that feels polished and fast, one that customers keep returning to over and over again. Regardless of how bad things are today, you can institute a framework to pay off your bug debt, while building and pushing features. An SLA system has built-in checks and balances to slow down feature development when things get serious and provides natural incentives for teams to pay attention to the quality of their software, leading to more productive and happier engineering teams in the long run.
Make a copy and get started!
This doc is meant to be a framework for establishing software quality metrics. on your desktop and get started.
Copy the doc
Here's an outline of the different parts of this toolkit:
Setup
Weekly Tracking
If you would like to try this technique and need help implementing it, the Coda team has graciously offered to help. Click this button to get assistance:
About me
Hi, I'm . After spending nearly a decade managing some of the brightest engineering teams at Facebook and YouTube, I’m taking a break and doing some writing, spending time with my family, and figuring out my next thing.
See the original post here:
👉 The time has come, head to to get started!
Want to print your doc?
This is not the way.
This is not the way.
Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.