Skip to content
dont exist centralised storage of grants and projectstags system works pretty bad, hard to find relevant projectyoung scientist cant connect w/ projects because dont have well-known proofsdata sets and other open data could be stored in different placesscientist cant share rare equipment because dont know about each other
Marketplace that combine in one place: grants from main platformsprojects/grants that could be live direct on platfrompeople w/ skills and equipmentsNatural language matching (based on description or search query)Reduce friction for new scientistCross-platform score
Comprehensive Analysis: By aggregating data from diverse sources using ORCID (allows aggregating from CrossRef, SCOPUS API, ResearcherID, DataCite, BASE), GitHub, the system provides a holistic view of a contributor's academic and coding contributions. This comprehensive analysis ensures a more accurate representation of a contributor's impact and expertise.Enhanced Matchmaking: The cross-platform score can facilitate better matchmaking between projects and potential contributors. Projects can identify contributors with the required expertise, while contributors can find projects aligned with their skills and interests.Reduction of Platform Biases: Different platforms can have biases based on their primary user base or purpose. By incorporating multiple platforms, this system can minimize the biases associated with any single platform.Time-Efficient: Instead of manually checking multiple platforms for contributor information or project details, stakeholders can get an aggregated score swiftly, saving time and effort.Dynamic Updating: Platforms like GitHub are constantly updated with new contributions. A system that frequently recalculates scores based on new data ensures up-to-date and relevant scoring.Spam and bad actor protection: A scoring system combats spam and malicious activity on digital platforms. Thresholds and Limitations, restrict users or content that fall below set scores, deterring undesired behaviors
Description and Profile Score: The process begins by taking the description and profile score of the scientist or the science grant/project as input.Cleaning text (nltk): Before the description can be analyzed, it needs to be cleaned. This step involves removing any irrelevant or redundant information and could include tasks like removing stop words, stemming, and tokenization. The Natural Language Toolkit (nltk) appears to be used for this purpose.Key Extractor (yake): After cleaning, the text is then passed through a key extractor, specifically the YAKE algorithm, to identify and extract the most relevant keywords from the description.Search by keys and score limit: These extracted keywords, along with the profile score, are then used as search parameters in ElasticSearch, a search and analytics engine that is most relevant for our needs. This step is geared towards finding the most relevant matches based on the given keywords and score.Create the TF-IDF vectors: To determine the similarity between the input description and potential matches, the Term Frequency-Inverse Document Frequency (TF-IDF) technique is used. This step involves converting the cleaned text of both the input description and potential matches into TF-IDF vectors.Calculate the cosine similarity: The similarity between the TF-IDF vectors is determined using cosine similarity. This metric gives a value between 0 and 1, where a value closer to 1 indicates a higher similarity.Text matching: Based on the cosine similarity values, the most relevant matches are identified.LLM explanation for matched texts: Finally, the Language Model (LLM) provides explanations for the matched texts, helping users understand why a particular scientist or project was matched with a given grant or project.Input: Description and profile score of scientist or project.Text Cleaning (using nltk):Remove stop words, stemming, tokenization.Keyword Extraction (using YAKE):Identify key terms from the cleaned description.Search in ElasticSearch:Use extracted keywords and score as search parameters.Text-to-Vector Conversion:Convert descriptions to TF-IDF vectors for similarity analysis.Cosine Similarity Calculation:Measure similarity between input and potential matches.Text Matching:Identify best matches based on similarity scores.Explanation using LLM:Provide context on why each match was selected.
Highlight that the platform has aggregated grants from numerous popular sources, providing a centralized hub for scientists to easily find grant opportunities.Clarify the platform's stance with grant organizations: While the platform showcases the grant opportunities, it isn't trying to compete with or replace grant organizations. Instead, it acts as an additional display window for their information.Emphasize the platform's commitment to open-source values.Introduce the mechanism of "first good issues" but with a twist tailored for the scientific community. Explain that just as open-source projects on platforms like GitHub tag certain tasks as "first good issues" for newcomers to tackle, this platform offers "first good research" opportunities.Detail how this works:
Using blockchain as open social graph unlock community power for building better suggesting algoritmsreputation transparencyZk-proofs KYC for matching science achievements w/ their profileDeriving a Generic Score
 Landing
Landing
Main defined problems for Open Sience
Our approach
Cross-platform score for easier matching
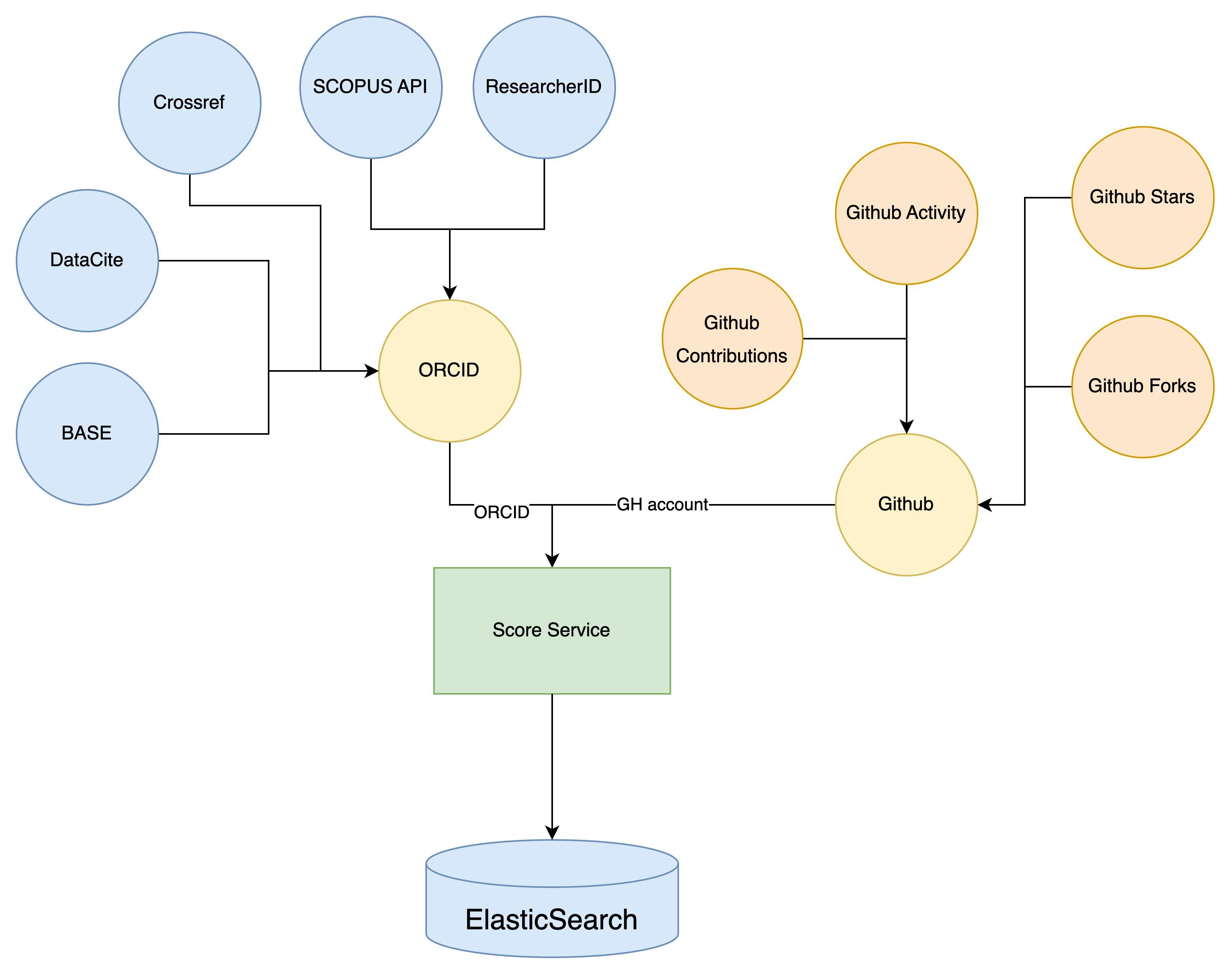
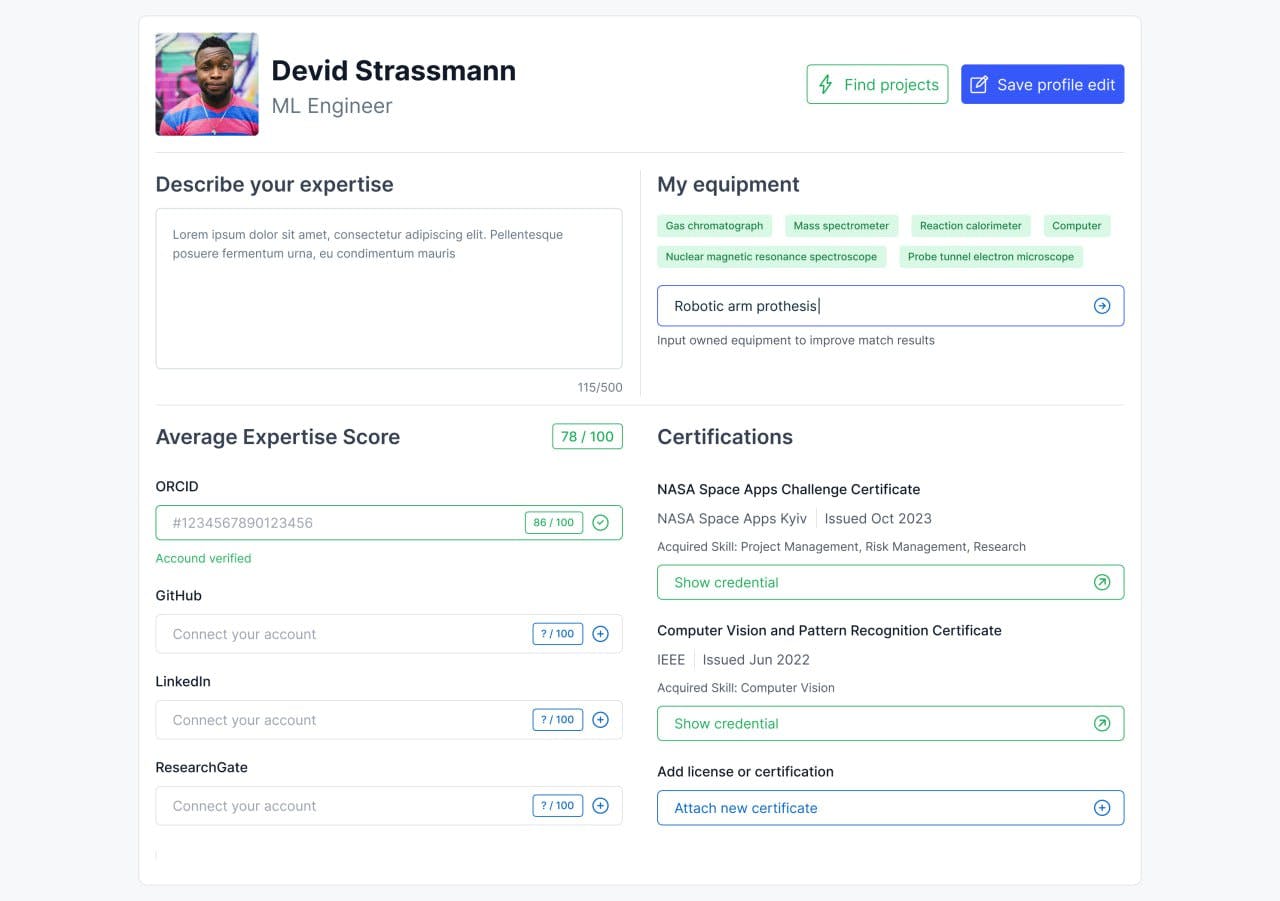
Our Matching system

Short description:
Code: [link]
Reduce friction for new scientist
New scientists often encounter barriers when trying to secure funding and collaborate on research projects. They face the daunting task of navigating through numerous grant sources, each with its own platform and application process. Additionally, these emerging scientists might not have an established reputation or sufficient "score" within the scientific community, making it challenging to join ongoing projects. Moreover, grant organizations often struggle with visibility, with their grant opportunities getting lost amidst the myriad of sources.
Grants Collection:

Open Source Code Culture:
If a scientist doesn't initially qualify for a project due to a low score or lack of experience, they can prove their capability by addressing a "first good research" challenge set by the project. Successful completion can then open doors to further collaboration.
Future improvements
General Marketplace Diagram:

References:
https://spotintelligence.com/2022/12/19/text-similarity-python/#1_Text_similarity_with_NLTK
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.