Skip to content
 Le bla-bla autour de l'IA
Le bla-bla autour de l'IA
L’intelligence artificielle a un côté magique qui fait que dès que l’on la colle à une thématique ou un produit, par miracle, un effet réseau des données est censé se produire, propulsant l’avantage concurrentiel de celle ou celui-ci. C’est beau et fait toujours bon effet dans une présentation:
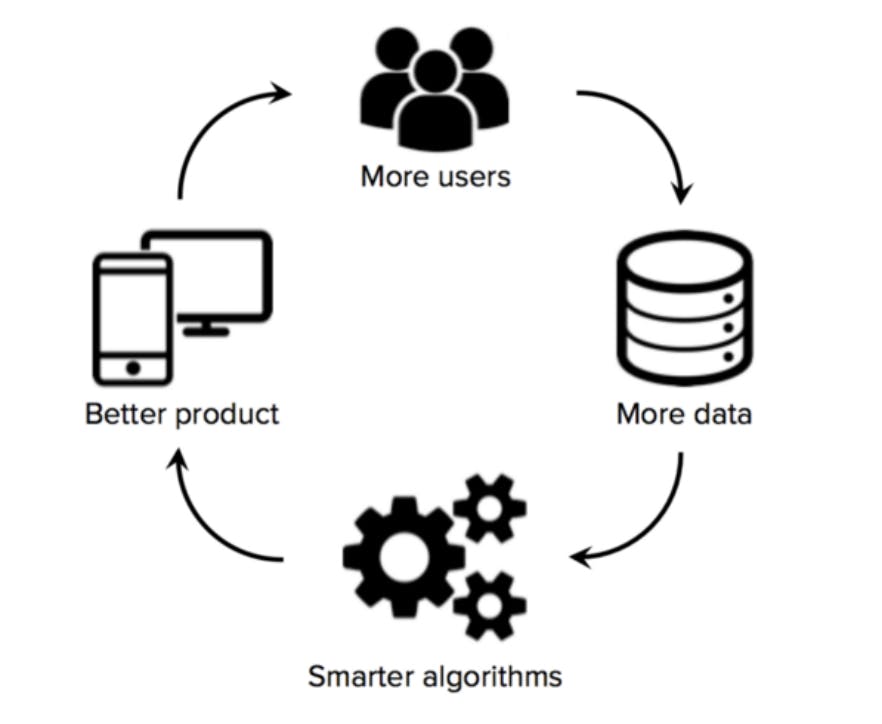
Une autre tarte à la crème est l’effet réseau lié à la possession de données. Le raisonnement est le suivant: plus on a de clients, plus on a de données et plus on a de données, mieux les algorithmes d’intelligence artificielle fonctionnent et permettent d’attirer de nouveaux clients. Prenez une idée, appliquez lui un algorithme d’intelligence artificielle et vous avez un effet réseau. Est-ce que l’ajout d’utilisateurs renforce le service pour l’ensemble de ceux-ci ? L’exemple de Netflix est une bonne illustration. Avec 160 millions d’abonnés, son système de recommandation doit être imbattable, lui donnant un avantage dans la course aux abonnés. Pourtant Disney lance un service de streaming en novembre et compte déjà plus de 26 millions d’abonnés. Partant de zéro, Disney a déjà un algorithme de recommandation performant...En fait Disney a acheté BAMTech en 2017, société technologique qui gérait le streaming d’HBO et de ligues sportives. BAMTech a apporté dans son escarcelle un savoir faire en apprentissage profond et données utilisateurs qui n’avait rien à envier à Netflix. Il y a deux éléments importants qui relativisent l’effet réseau des données:
1/ Il est relativement facile dans la majorité des cas usuels d’acquérir des données de base pas cher ou même de les récupérer (en surfant sur le web). Des données plus spécialisées peuvent valoir plus cher mais elle ne découlent pas d’abonnés à un service (exemple des données médicales).
2/ Il est important d’obtenir une masse critique de données mais au delà d’un certain point, l’acquisition de données devient trop chère par rapport à leur utilité marginale. On se retrouve dans le cas des sociétés de logiciel dont le coût d’acquisition des clients devient prohibitif par rapport à la valeur qu’ils vont apporter.
Stitch fix illustre bien l’écart entre le discours et la réalité des affaires. Cette société fournit sous abonnement des habits choisis par un hybride de stylistes et d’intelligence artificielle. Le pitch est l’effet réseau magique: plus de données sur les abonnés permet de mieux calibrer le service, de satisfaire les clients, de leur vendre plus et d’en faire venir d’autres, ce qui augmente la base de données, etc. Le coût d’acquisition du client est donc censé baisser avec le nombre. Les résultats de l’entreprise ne corroborent pas cette thèse: les charges (essentiellement commerciales) montent plus vite que le chiffre d’affaires. La réalité est probablement qu’au départ, l’offre de Stitch Fix a séduit les fans, principalement des femmes, et que la société doit viser maintenant des clientèles moins convaincues du service (les hommes notamment). Encore une fois, où est l’effet réseau des données ?
Prétendre qu’il existe un effet réseau des données revient à admettre une supériorité intrinsèque à la propriété des données. Du seul fait de cette propriété l’algorithme de prédiction serait supérieur à ce qu’on peut faire par ailleurs, s’auto-améliorant constamment et laissant sur place la concurrence. Cela reste à démontrer: si un algorithme est efficace à 25%, c’est à dire a un taux d’erreur de 75 %. Un algorithme plus précis à hauteur de 30% aura un taux d’erreur de 70%. L’amélioration du taux d’erreur est de 7 % et l’algorithme reste très imprécis. Si en revanche un algorithme est efficace à 98 % avec un taux d’erreur de 2 %, une plus grande précision de l’algorithme à 99 % représente une amélioration de 50 % du taux d’erreur. Cela fait la différence.. On peut donc d’abord s’interroger sur la qualité de la prédiction de l’algorithme. Pour la plupart des usages, c’est à dire la prédiction du goût des utilisateurs, l’algorithme est à mon avis peu fiable à la base. Dès lors, une amélioration, même de 20 % (passage de 25 % à 30 % ne fera pas la différence). Netflix réussit car il a su créer la liquidité maximale sur sa plateforme, à coût d’investissements massifs dans les films et séries, non parce que les données lui permettent de cerner le mieux possible les goûts des utilisateurs et ainsi de mieux choisir les films. La meilleure preuve: Ted Sarandos (culture Hollywood) a récemment été nommé co-CEO avec Reed Hastings (culture Silicon Valley). En revanche pour une application de traduction, médicale, de détection de fraude, où le taux d’erreur est bien plus faible, les données peuvent faire la différence. C’est ainsi que Deepl (issu de Linguee) est à mon sens bien meilleur que Google Traduction, car il a accès à toutes les données de cette encyclopédie linguistique. Je ne suis pas persuadé que Deepl ait une puissance de calcul qui dépasse celle de Google ou des ingénieurs plus astucieux. Leur supériorité en matières de données fait la différence.
Mais c’est un cas rare. En effet, quand la qualité de la prédiction algorithmique est bonne, elle est le plus souvent liée à des données faciles à obtenir, souvent publiques et faciles également à traiter. L’intelligence artificielle fait alors la différence par rapport à l’homme, mais les sociétés qui l’utilisent se neutralisent mutuellement, car elle est facile à appliquer. Prenons l’exemple des taxis. Leur avantage concurrentiel, en dehors du numerus clausus, reposait sur la connaissance approfondie d’une ville nécessitant trois ans d’apprentissage et leur permettant de choisir le plus court trajet pour aller de A à B. Les applications de type Waze reposant sur l’intelligence artificielle ont anéanti l’avantage des taxis: n’importe quel détenteur de permis B peut faire leur métier aussi bien avec plus de transparence. L’intelligence artificielle a décimé la profession de taxi. Pourtant, elle n’a pas donné d’avantage à Uber ou Lyft. Ces derniers peuvent vanter l’avantage des données qu’ils collectent et qui les rendent plus intelligents. C’est le pitch marketing. Voici ce qu’affirmait Uber dans son document d’introduction en bourse:
Réseau massif. Notre réseau massif, efficace et intelligent se compose de dizaines de millions de conducteurs, de consommateurs, de restaurants, d'expéditeurs, de transporteurs, de vélos et de scooters électroniques sans station d'accueil, ainsi que de données sous-jacentes, de technologies et d'infrastructures partagées. Notre réseau devient plus intelligent à chaque voyage. Dans plus de 700 villes du monde entier, notre réseau permet à des millions de personnes, et nous espérons qu'à terme, des milliards, de se déplacer en appuyant sur un bouton.
En fait l’avantage d’UBER, et de toute société de ce type, repose sur la liquidité de sa plate-forme, liquidité obtenue par des $ milliards investis pour attirer chauffeurs et passager. L’avantage doit être gagné ville par ville, le transport étant local. Cela explique la floraison de compétiteurs et le sang versé pour obtenir la suprématie. L’intelligence artificielle a permis Uber mais ne lui a pas donné de supériorité car elle créé une routine facilement réplicable. C’est tout le problème avec la généralisation de l’IA facilitée par les bibliothèques Open source comme Tensorflow. Des prédictions réalisées par l’homme vont être remplacées par des prédictions algorithmiques, rendant obsolètes de nombreuses tâches, sans créer pour autant d’avantages pour les nouveaux. Plus les données seront homogènes et faciles à traiter (le passé étant un bon indicateur de ce qui va se passer dans le futur), moins l’intelligence artificielle sera différentiante. La technique de Google avec TensorFlow est la même qu’il utilise avec Chrome ou Kubernetes. Je l’ai mentionnée dans mon article
L’idée est toujours la même: prendre le contrôle d’une technologie qui réduit les frictions antérieures (Android, Chrome, Kubernetes, TenserFlow), la rendre open source pour en généraliser l’adoption, établir sa version améliorée propriétaire et peser sur les standards de place pour structurer le marché à sa convenance. Chrome est le cas d’école. Google a rendu open source le bloc navigateur Chromium, objet d’un de ses programmes de recherche, lequel a servi pour concevoir d’autres navigateurs (Opera, Firefox et maintenant Microsoft Edge, une reconnaissance de la défaite de Microsoft Explorer). Puis Google a rajouté à Chromium des fonctionnalités propriétaires (plug in) dans un navigateur qu’il a appelé Chrome. Ce dernier s’est montré supérieur à ses concurrents open source ou non.
Google veut simplement banaliser l’intelligence artificielle et garder la supériorité grâce à sa puissance de calcul et ses mathématiciens capables d’ajouter un petit plus aux algorithmes pour faire toute la différence (comme le Medallion Fund pour la prévision financière).
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.