Skip to content
Share
Explore
Horizontal Pod AutoScaling for Browserless
 Testing and Troubleshooting
Testing and Troubleshooting
Testing and Troubleshooting
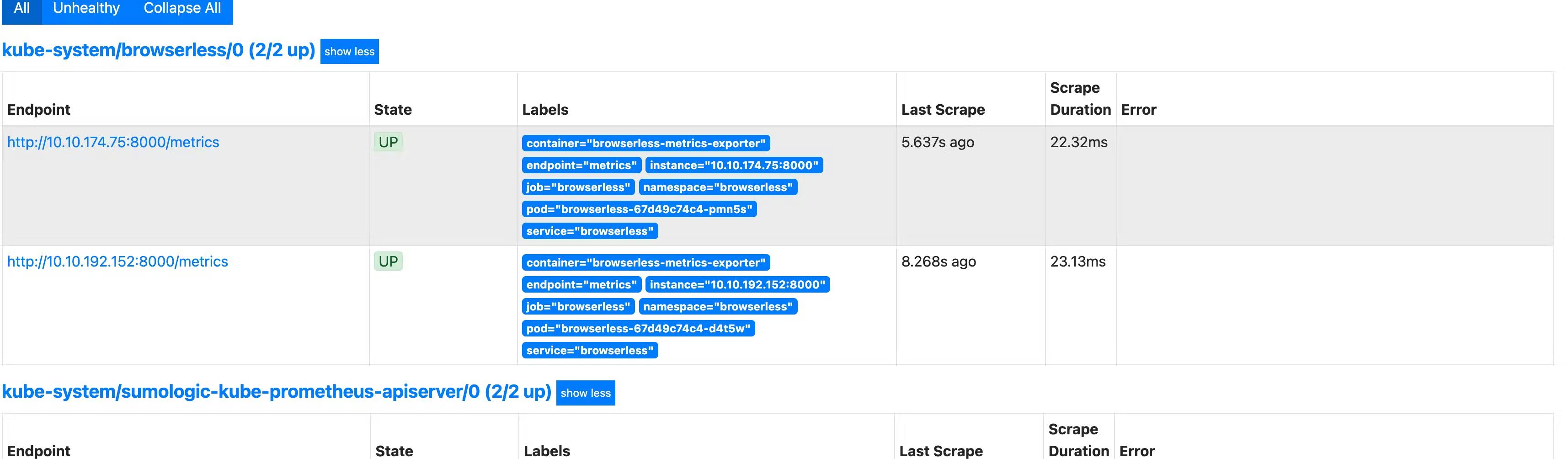
Testing if metrics are flowing from into Prometheus.
Service Monitor
Ports and Endpoints
Internal API
X86 Images
Format
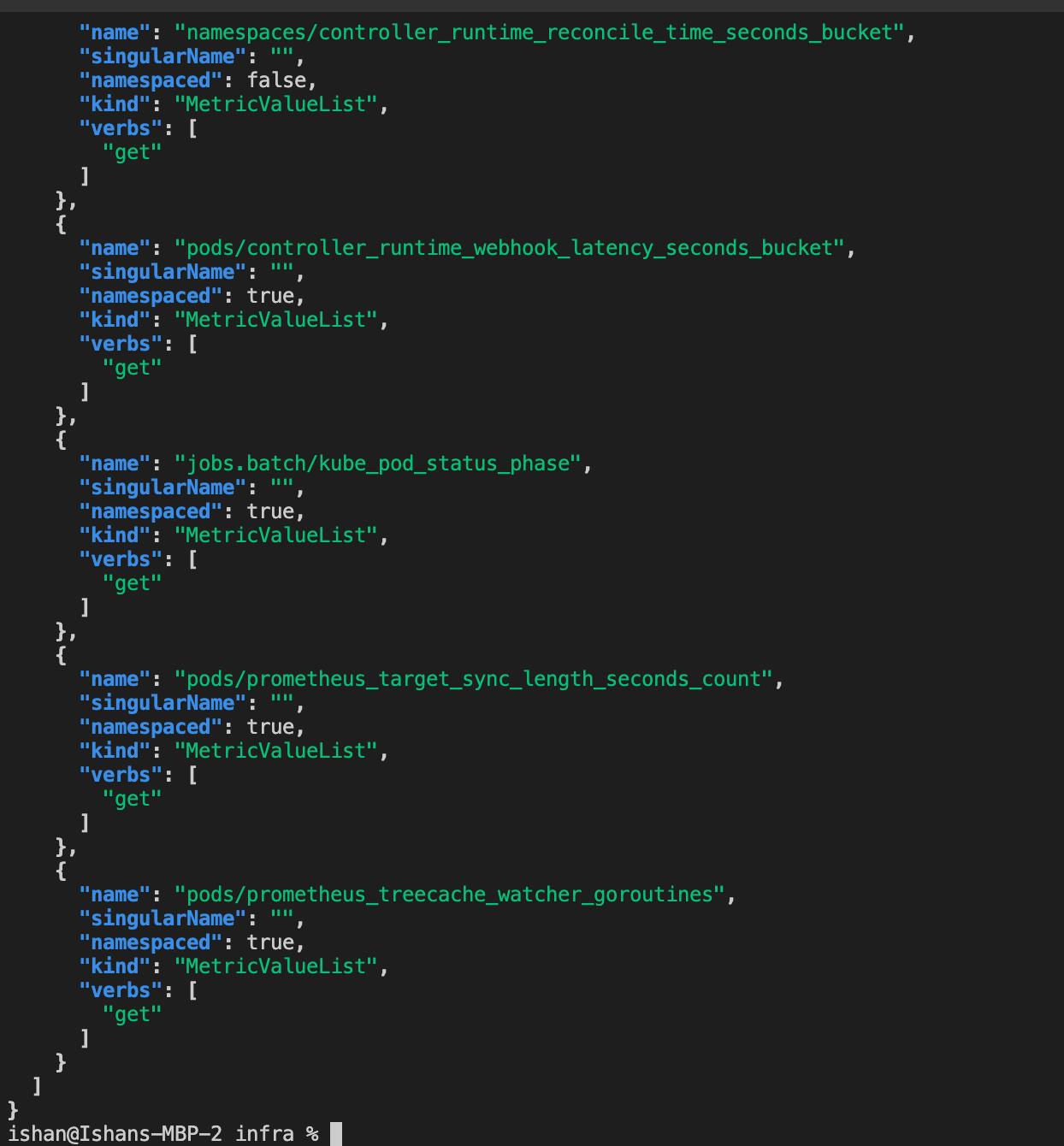
Testing if metric are flowing from Prometheus to Kubernetes
Custom metrics API
Metric URLs
Troubleshooting with logs
Prometheus Adapter and HPA info
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ⋯ next to your doc name or using a keyboard shortcut (
CtrlP
) instead.