Skip to content

— One central doc managed by your HR team with read-only access for others. The people team can sync a view of just one team’s details into their team hub doc. — Managers can store all their team’s performance reviews in one private table and create views for individuals that can be synced into their 1:1 docs. This means a manager can keep an overview of their team, but share the results privately with each report.
Share
Explore

Our customers often ask us how to connect two docs together. Today, we’re launching our answer to that question. It’s called Cross-doc, and it enables you to pull data across documents.

Originally, we built to integrate Coda with the other apps your team uses. A few months in, we realized the number one Packs request wasn’t for another service, it was for another Coda doc.
Cross-doc lets you pull data from one doc into another, so you can retain that ever-elusive single source of truth. We expect this building block will likely reshape how you organize information in Coda. Instead of one giant doc with views for every team, you could now have one Coda doc for the master data set, feeding into separate team docs.
Where it all began
Our makers have been asking to connect docs for a long time. Over the last year, we’ve built several prototypes in hackathons and tested a couple approaches in our own docs. But none felt quite right until now. Cross-doc hasn’t been an easy design challenge, so consider this our humble first iteration.
Why was it so hard?
Putting aside technical hurdles, we had to start by understanding how a table should work when it wasn’t in its original doc. Who can make edits? What data should editors see? We wanted to make sure the solution had the security and integrity of your data at its heart.
Back to building blocks
Like all of the best Coda docs our breakthrough came from our building blocks.
At the end of last year, we launched which let makers connect docs with other data sources. Then this summer, we launched which enabled syncing external data into a doc. Now, we’re adding the missing piece, which is a new scoped API that enables pulling data from a specific table, not the whole doc.
The last piece is key for Cross-doc, as it enables us to create a UI to share parts of docs. It means you only share what you need and nothing more.
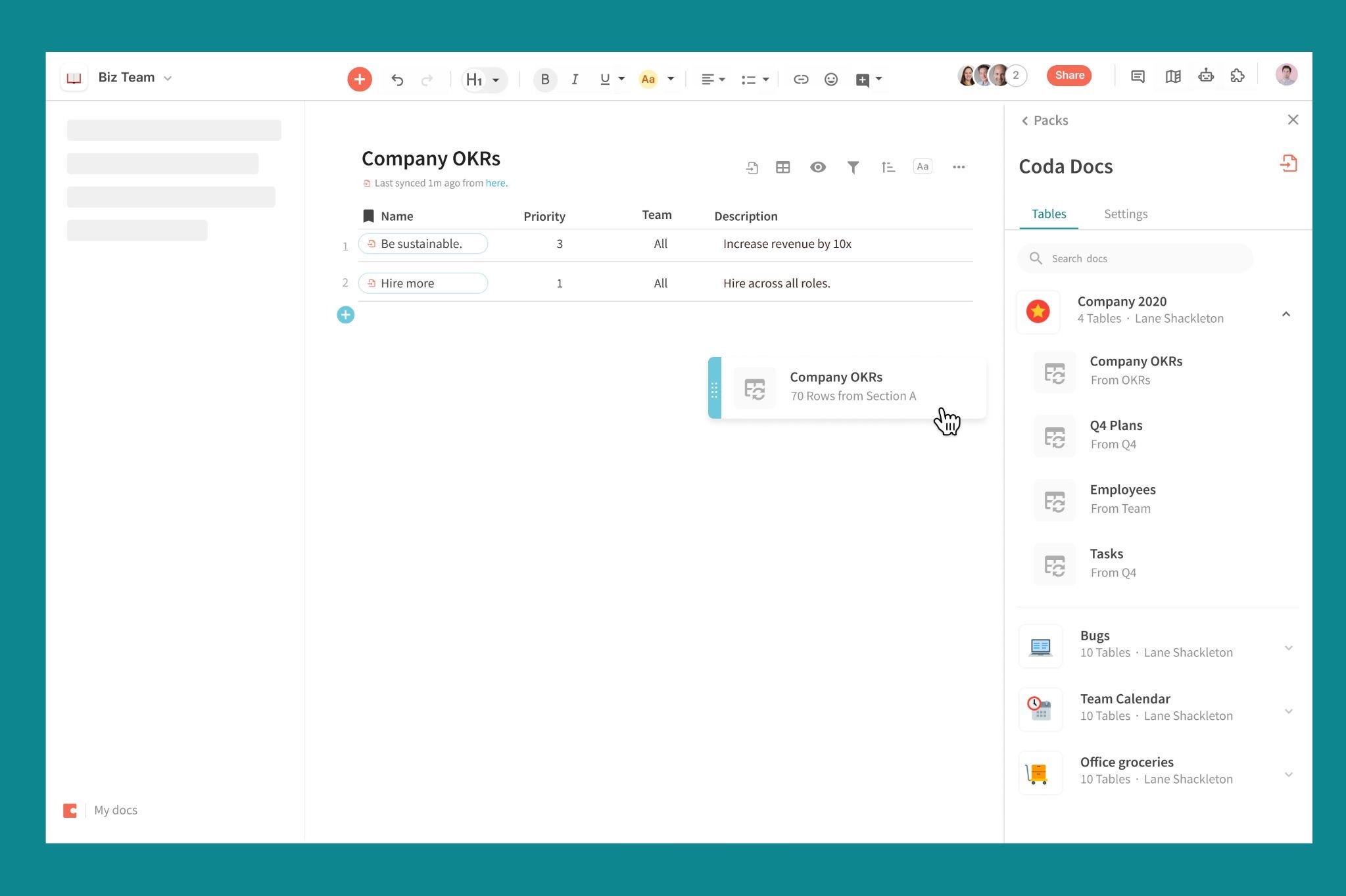
To go a level deeper, we operate on a what you see is what you get model, meaning we only sync the data that is shown in the original doc, not the hidden rows or columns. This means you can keep sensitive data completely hidden when you sync a table from one doc to another. For example, you could use cross-doc to distribute feedback for each of your direct reports from a master feedback doc and hide columns containing information from other direct reports.
We started with one-way sync to protect your data so no one can edit a table from another doc. In the future, we’ll expand this to allow edits the other way in certain scenarios.
Fun use cases to get started
Given some of these nuances, we want to share some of the best use cases we’ve seen for Cross-doc both from our own experience and from our beta customers.
(1) Single source of truth
We heard many makers use the term ‘single-source of truth’ in our research and it quickly became our target scenario for Cross-doc. It’s ideal for situations when there is a central doc that is updated as your source of truth and teams want to use that data in their own docs.

— Update your OKRs in a central doc but share your personal OKRs into your own to do list or team doc to keep you focused.(2) Combine multiple sources
It’s possible to do deeper rollups and aggregates from multiple docs into one, but this case takes a little more work. To do this, we put together a helpful to show you some different approaches, ranging from simple to complex.

We would love to know how you’re using Cross-doc with your teams so let us know your thoughts in the . We’re listening closely and look forward to your feedback!
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.