Skip to content

Có nguồn thông tin đáng tin cậyCấu trúc thông tin đó theo cách cho phép công cụ tìm kiếm trả lời các truy vấnKho tri thức (KR)Cơ sở tri thức (KB) thường được gọi là biểu đồ tri thức (KG)Một thực thể hoặc đối tượngMột kiểu thực thể hoặc lớpMối quan hệ thực thể
Share
Explore
Knowledge graph
SƠ ĐỒ TRI THỨC CỦA GOOGLE LÀ GÌ?
Sơ đồ tri thức của Google là Cơ sở tri thức gồm các thực thể được cấu trúc thành một biểu đồ được gọi là Sơ đồ tri thức.
Trong trường hợp bạn không biết câu nói đó có nghĩa là gì, đừng lo, tôi sẽ cố gắng tách nó ra và giải thích từng phân đoạn một. Sau đó, tôi sẽ cố gắng ghép tất cả lại với nhau thành một câu mạch lạc mà người bình thường có thể hiểu được.
Tôi chắc chắn coi mình là một giáo dân và điều đó có nghĩa là tôi hy vọng sẽ sử dụng ngôn ngữ dễ hiểu.
Thật thú vị khi lưu ý rằng Sơ đồ tri thức của Google tương tác trực tiếp với SERPs. Nơi rõ ràng nhất để thấy điều này là Bảng tri thức của Google . Bảng tri thức là một cách để người dùng cuối tương tác với thông tin thực thể trong Sơ đồ tri thức.
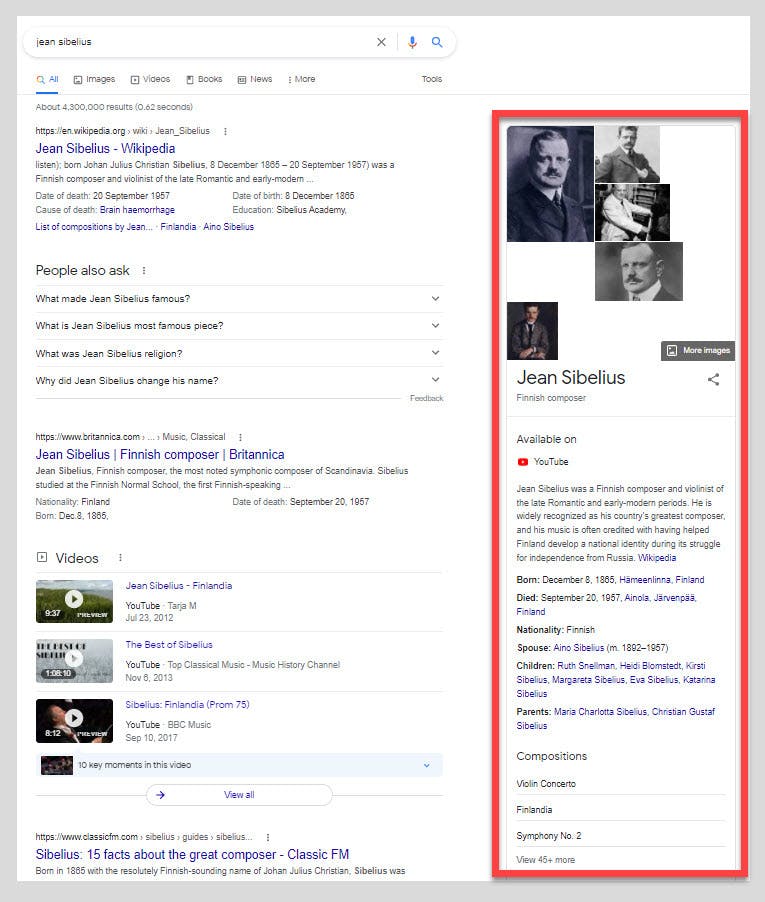
Để bắt đầu tìm hiểu Sơ đồ tri thức của Google, trước tiên chúng ta cần hiểu tại sao các công cụ tìm kiếm đang phát triển theo hướng tìm kiếm ngữ nghĩa.
TÌM KIẾM NGỮ NGHĨA
Nói một cách đơn giản, một công cụ tìm kiếm ngữ nghĩa được thiết kế để tương tác với những người sử dụng ngôn ngữ mà một người sẽ sử dụng.
Tại sao công cụ tìm kiếm làm điều đó?
Chà, nếu bạn đã ở đây một thời gian, bạn có thể nhớ việc gõ một truy vấn vào công cụ tìm kiếm là như thế nào cách đây mười lăm hay hai mươi năm. Nếu bạn nhớ lại thì nó rất không chính xác. Bạn sẽ cố gắng tìm ra những từ thích hợp để nhập vào công cụ tìm kiếm và sau đó bạn sẽ phải tìm kiếm xung quanh để tìm ra tài nguyên mà bạn đang tìm kiếm.
Lý do cho điều này là các công cụ tìm kiếm vào thời điểm đó không có cách nào hiểu được truy vấn của bạn. Họ cũng không thể hiểu ý nghĩa của nội dung trực tuyến để trả lời câu hỏi của bạn.
Trái ngược với trải nghiệm của bạn khi sử dụng các công cụ tìm kiếm ngày nay. Bạn có bao giờ nhận thấy rằng Google gần như có thể mang đến cho bạn một cách trực quan nội dung không chỉ liên quan đến truy vấn của bạn mà còn có thể thường trả lời trực tiếp truy vấn của bạn trên các trang kết quả không?
Vì vậy, làm thế nào để Google làm điều đó?
Xử lý ngôn ngữ tự nhiên (NLP).
Xử lý ngôn ngữ tự nhiên của Google là khả năng 'hiểu' và tương tác với ngôn ngữ tự nhiên của con người.
Và…
Để đạt được khả năng xử lý ngôn ngữ tự nhiên, họ cần cơ sở dữ liệu thông tin có thể đọc được bằng máy được cấu trúc theo cách bắt chước cách con người tổ chức thông tin .
Bằng cách cấu trúc thông tin theo cách này, các công cụ tìm kiếm có thể hiểu' truy vấn của người dùng và đưa ra các tài nguyên liên quan để trả lời truy vấn bằng cách 'hiểu' nội dung trực tuyến.
Mặc dù máy móc không thực sự hiểu ngôn ngữ nhưng chúng có thể bắt chước sự hiểu biết.
Bây giờ, để tổ chức thông tin theo cách cho phép máy móc thực hiện việc này, chúng cần chia ý tưởng và thông tin thành các thực thể.
THỰC THỂ GOOGLE LÀ GÌ?
Một thực thể của Google được Google định nghĩa là "Một sự vật hoặc khái niệm là số ít, duy nhất, được xác định rõ ràng và có thể phân biệt được." Nói một cách đơn giản, các công cụ tìm kiếm có cơ sở dữ liệu về các thực thể và các cơ sở dữ liệu này bao gồm thông tin về thực thể như tên, loại, thuộc tính và cách các thực thể liên quan đến các thực thể khác.

một cấu trúc bắt chước cách mọi người cấu trúc thông tin.
Thực thể là những khối xây dựng nhỏ nhất cần thiết để tổ chức thông tin theo cách này.
Được rồi, bây giờ chúng ta đã hiểu biết cơ bản về các thực thể, hãy chuyển sang biểu đồ tri thức.
HIỂU SƠ ĐỒ TRI THỨC CỦA GOOGLE
Sơ đồ tri thức của Google được tạo thành từ các bộ phận cấu thành khác nhau. Lý do cho điều này là để các công cụ tìm kiếm trả lời các truy vấn của người dùng, chúng cần:
Điều này đưa chúng ta đến:
Hãy đi sâu vào cả hai.
KHO TRI THỨC (KR)
Kho tri thức là nguồn thông tin mà các công cụ tìm kiếm sử dụng để xây dựng cơ sở tri thức. Chúng là danh mục các thực thể sắp xếp các thực thể thành các loại thực thể.
Chúng có thể tùy chọn bao gồm các mô tả về các thực thể cũng như các thuộc tính của thực thể. Các kho tri thức này tồn tại ở dạng có cấu trúc hoặc bán cấu trúc.
Ví dụ hoàn hảo về kho kiến thức là Wikipedia. Mỗi bài viết Wikipedia mô tả một thực thể cụ thể, biến nó thành một danh mục thực thể.
Hơn nữa, mỗi bài viết được gán cho các danh mục và chúng ta có thể xem các danh mục này dưới dạng các loại thực thể.

Vì vậy, trong ảnh chụp màn hình ở trên, bạn có thể thấy các danh mục dành cho thực thể 'xử lý ngôn ngữ tự nhiên'. Như bạn có thể thấy, xử lý ngôn ngữ tự nhiên là một loại thực thể. Hơn nữa, nó là một tiểu thể loại của ngôn ngữ học tính toán. Ngôn ngữ học tính toán là một tiểu thể loại của nhận dạng giọng nói, v.v.
Các bài viết trên Wikipedia cũng hiển thị mối quan hệ giữa các thực thể bằng cách thêm các siêu liên kết giữa các bài viết. Chúng cũng bao gồm thông tin về các thuộc tính và mối quan hệ của thực thể.
Tất cả thông tin này đều ở định dạng bán cấu trúc.
Kho kiến thức bán cấu trúc
Dữ liệu bán cấu trúc chỉ đề cập đến thông tin có một số cấu trúc như đánh dấu HTML bao gồm tiêu đề, đoạn văn và bảng.
Nói một cách đơn giản Wikipedia là một Kho lưu trữ kiến thức bán cấu trúc.
Kho tri thức có cấu trúc
Mặt khác, dữ liệu có cấu trúc (hoặc cơ sở dữ liệu quan hệ) chỉ đơn giản đề cập đến dữ liệu có cấu trúc hoặc lược đồ được xác định trước. Dữ liệu có cấu trúc thường được tổ chức thành các bảng. Điều này có nghĩa là mọi trường được chỉ định bởi lược đồ phải được cung cấp một giá trị (được phép).
Khi các công cụ tìm kiếm có thông tin có cấu trúc hoặc bán cấu trúc này, nó vẫn chưa được sắp xếp theo cách mà các công cụ tìm kiếm có thể sử dụng nó để tìm kiếm ngữ nghĩa.
Bước tiếp theo là cơ sở tri thức (hoặc biểu đồ tri thức).
CƠ SỞ TRI THỨC HOẶC SƠ ĐỒ TRI THỨC
Điều quan trọng là phải hiểu rằng để phần mềm AI thực hiện các tác vụ NLP phức tạp, chẳng hạn như hiểu các truy vấn của người dùng, chúng cần dữ liệu được cấu trúc theo một cách cụ thể.
Nói cách khác, dữ liệu có cấu trúc ở dạng bảng hoặc dữ liệu bán cấu trúc như các bài đăng trên blog Wikipedia không cung cấp cho hệ thống AI những gì chúng cần để xử lý ngôn ngữ của con người.
Thay vào đó, thông tin cần được cấu trúc theo cách tương tự như cách mọi người tổ chức thông tin trong tâm trí họ.
Để làm điều này, Cơ sở tri thức phải lấy thông tin từ Kho tri thức và sắp xếp nó thành các xác nhận về thế giới. Những xác nhận này mô tả các thực thể và cách chúng liên quan đến nhau. Tôi sẽ mô tả điều này chi tiết hơn sau.
Để làm được điều này, các công cụ tìm kiếm cần một mô hình dữ liệu được gọi là Khung mô tả tài nguyên (RDF). RDF cung cấp một tập hợp các câu lệnh tiêu chuẩn mô tả các thực thể hoặc tài nguyên.
ĐỊNH DẠNG MÔ TẢ TÀI NGUYÊN (RDF)
RDF là một ngôn ngữ được thiết kế để mô tả các thực thể và các mối quan hệ của chúng. Nó được tạo thành từ các tài nguyên.
Một tài nguyên có thể đề cập đến:
Bộ ba ngữ nghĩa là một bộ ba thực thể được sắp xếp thành một câu dưới dạng chủ ngữ-vị ngữ-tân ngữ. (Được biểu thị dưới dạng biểu đồ, một câu lệnh RDF được biểu thị bằng một nút cho chủ ngữ, một cạnh đi từ chủ đề này sang đối tượng khác và một nút cho đối tượng.)
Chủ ngữ và vị ngữ được biểu thị bằng mã định danh số riêng của chúng được gọi là URI. Đối tượng của câu lệnh có thể được biểu thị bằng URI hoặc có thể là một giá trị bằng chữ.
Đối với những bạn là những người học trực quan, đây là một minh họa:

Chủ ngữ của bộ ba là một thực thể. Vị ngữ có thể là một loại thực thể hoặc mối quan hệ. Ví dụ: quốc tịch, ngày sinh, tên, v.v. Đối tượng là một thực thể khác hoặc một giá trị, chẳng hạn như một chuỗi biểu thị tên hoặc một số đại diện cho một ngày.
Vì vậy, ví dụ, hãy xem câu đầu tiên trong bài viết trên Wikipedia về Mike Tyson:
Michael Gerard Tyson (sinh ngày 30 tháng 6 năm 1966) là một cựu võ sĩ chuyên nghiệp người Mỹ đã thi đấu từ năm 1985 đến năm 2005.
Hãy phân tích điều đó một cách trực quan.

Trong hình minh họa ở trên, tôi đã trình bày cụm từ đầu tiên dưới dạng bộ ba.
Chủ ngữ là thực thể 'Mike Tyson', vị ngữ là 'ngày sinh' và '1966-06-30' là tân ngữ. Tôi đã đặt một hình chữ nhật xung quanh Mike Tyson để thể hiện rằng Mike Tyson là một thực thể. Mặt khác, 1966-06-30 không phải là một thực thể mà là một giá trị nên tôi đã đưa nó vào dấu phẩy đảo ngược.
Đây là một đại diện trực quan của toàn bộ câu:
Đi xa hơn, bất kỳ thực thể nào tồn tại trong ví dụ trên đều có thể được coi là chủ thể trong một bộ ba khác, dẫn đến một mạng lưới lớn các thực thể và mối quan hệ phức tạp.
<iframe src="https://giphy.com/embed/YnexM9LwlwGu4Z1QnS" width="480" height="480" frameBorder="0" class="giphy-embed" allowFullScreen></iframe><p><a href="
GIPHY</a></p>
LỜI CUỐI CÙNG VỀ SƠ ĐỒ TRI THỨC
Bây giờ bạn đã có hiểu biết cơ bản về sơ đồ tri thức là gì. Hơn nữa, bạn nên có hiểu biết của một người bình thường về thông tin được lưu trữ trong biểu đồ tri thức và bạn cũng nên hiểu thông tin đó đến từ đâu.
Mặc dù không có chiến lược khả thi nào trong bài đăng này, nhưng tôi cảm thấy kiến thức này là nền tảng cơ bản để hiểu SEO ngữ nghĩa sẽ giúp bạn tiến xa hơn trên con đường trở thành ngôi sao SEO.
Và sự hiểu biết dẫn đến những hiểu biết sâu sắc có thể thực hiện
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.