Skip to content
We look at what supporting evidence the idea has (e.g. market research, surveys, successful A/B experiment)Based on the evidence we give the idea a confidence score (details below) that indicates how sure we are now that this idea is a winner.If confidence is high we can go ahead with building and launching the idea.If confidence is not high we can decide to test the idea further (for example run a user study) to produce more evidence, to de-prioritize the idea in favor of other ideas, or to kill it altogether.Our level of investment in the idea should always stay proportional to our level of confidence in it. That’s right, no more big CEO pet projects that have no supporting data — ideas have to live and die on their on merit.
Increasingly harder tests — Many more ideas can survive the test of convincing your coworkers and managers to support the project, than the test of convincing users to pay for a min-viable-product (MVP). As you move forward in testing probability drops sharply, so an idea that survives the later stages is orders of magnitude more likely to be good than one that was subjected just to early tests.More reliable predictions — Earlier validation steps rely mostly on subjective opinions, projections and interpretations by individuals and groups. Research have Learning — as you go through the steps of validation you also learn more: about users, the market and how well your idea fits both. This gives you a chance not just to validate your idea, but also to improve it, usually long before it is launched. In fact most great ideas are not born great (no eureka moment), they become good through the process of testing, learning and refinement/pivots.
You think this is a good ideaYou perceive yourself as a smart and capable product personYou feel your product ideas are usually pretty good (sometimes even brilliant).You can clearly articulate why this is going to help the users and the companyYou have a short and elegant elevator pitchYou have a polished pitch deckThe idea matches your company’s or investor’s vision or strategyThe idea is inline with a current industry trend/buzzword.Outside research reports could be interpreted to support the idea.The idea seems to be aligned with macro trends in economy/societyThe idea fits a current product development or design methodology/philosophyThe team thinks it’s a good ideaManagement thinks it’s a good ideaAn external expert thinks it’s a good ideaAn investor thinks it’s a good ideaTech press thinks it’s a good ideaBack-of-the-envelope calculations (e.g. funnel numbers) show good potentialEngineering and UX feel the idea is feasibleEffort estimates from the team converge into a reasonable project timeframeA draft business model or business plan suggest good business-viability.2–3 data points in your product data support the ideaSales say it’s a top requestYou’ve spoken to 1–3 customers who seem interestedOne competitor has it implementedSurveys you conducted or commissioned clearly shows user/customer support for the ideaSmoke tests (for example a “fake door” ad campaign) get strong positive results (for example high ad CTR).Multiple/all competitors have it.Significant amount of product data across multiple months show support for this ideaA customer support/success report surfaces this as a top request by multiple customersYou’ve interviewed 20+ potential users/customers and 70%+ of them say they would use this and/or be willing to pay for it.You ran a usability study with 10+ users and 80%+ of them understood the idea, were able to use it, and said they would use it.You ran a successful small scale concierge MVP study with 1–5 users.You launched 2–4 week longitudinal study and 70%+ of participants kept using the product and were interested to buy or continue using at the end of the test.You’ve built an MVP and had 50+ active users/customers that at willing to use/purchase and are interested.You launched an alpha or beta version to 20+ early tester customers.You’ve ran an A/B test and the experiment group shows the key metrics you outlined, and no decline in other key metrics. All results are statistically significant with p-value of 5% of below.The feature gets repeat usage from a significant % of usersCompared to a 5% holdback group the user group that got the product change demonstrate better product stats (e.g. better retention, time spent)Customer support/success reports shows very positive feedback from usersBusiness metrics have improved since the launch12–24 months after the launch you have:Positive user feedback outweighs negative 10-to-1Metrics show strong repeat usage of the new featureBusiness metrics went up and stayed there
Too slow — Intuitively going full-throttle on an idea seems like the quicker way to put get to market. Teams are encouraged to “Launch fast”, “Launch and iterate”, and “Fail fast”. There are two fundamental flaws in this logic: a) Once launched it’s much harder to iterate on a product for both internal and for external reasons. In practice most underwhelming launches stay largely unchanged (and unused) until they’re eventually deprecated years later. It’s much easier and much more efficient to iterate while the product is still in development. b) Execution and learning are not mutually exclusive — It is to do both same time with marginal or zero time-to-market penalty.Too risk averse — For years we were told to build a vision, a strategy and then launch boldly according to them. The Big-bet/Moonshot/10x philosophy also seems at odds with confidence scoring as there’s a belief that user/market tests produce only “incremental” innovations. As far as I know there’s no research to support any of these claims. Certainly we’ve seen big successful ideas launched without thorough validation in the past, but this can simply be an outcome of confirmation bias — we’re not thinking of all the (many more) big ambitious projects that flopped or of all the good ideas that were left on the sideline. In fact by forcing teams to put more eggs in fewer baskets your incentivizing them to be more risk-averse and choose a project that is (perceivably) less likely to flop. By supporting many cheap experiments you allow teams to be more adventurous and to really go all in when a winner is detected.You can’t learn how users will behave before launching — Again I don’t have research to back this up, but my experience has been that you are rarely surprised at launch day if you’ve already had hundreds or thousands of early test users use the product and give you feedback and data. It’s not foolproof method, but you solidly increase the odds of success by confidence scoring, and as in all investment problems, it’s not about always winning, but about winning more.

Evidence scores — the acid test of your ideas
Finding and building the next big idea is the holy grail of any tech company. Unfortunately the statistics are against us: when most ideas turn out to produce no impact or even negative impact, and at least suggests that you need 3000 raw ideas to produce one commercial success. Consequently most “big bet” projects flop causing a lot of wasted investment. Some think that this us is just the way it has to be — with big ideas comes big risk, however the billion dollar question is: is there a way to tell if an idea is any good before making the big investment?
As it turns out there is, and it’s not even very complicated to practice:
To make this less abstract I created two simple tools you can use right away.
UPDATE: I’ve since created a third tool that combines both – the Confidence Meter (you can download it for free), but I recommend reading this post for deep background on the motivation behind the tool.
Tool #1 — Quick reference table

If you’re short on time just use the following chart. On the left I listed some of the most common ways people and companies validate ideas, and on the right how much confidence can be gained from each.
As you can see the activities we tend to perform early on in a project, while important, don’t really verify that the idea is any good. A good pitch and supporting “market research” don’t give us much confidence. In fact statistically speaking we must be quite skeptical of an idea at this stage, just because very few ideas are winners. It’s only the latter tests that give us any substantial proof of validity. Here’s why:
that both individuals and
struggle with tough analytical problems such as predicting which idea is going to fare better, and end up generating both both false positives and false negatives. For example many ideas (probably most) that succeed in getting funding are not necessarily good, while ideas that fail to get funding are not necessarily bad. Hence the “get funded” test is not a very reliable predictor. On the other hand an A/B experiment is a much more reliable predictor (though not perfect) of future performance.The unfortunate fact is that most companies miss the difference between low medium and high confidence and quite happy to launch projects with only Very Low to Medium confidence. Let’s look at some of the most common false signals and misconceptions.
Sign up to to get product management articles, tools, ebooks, and early-access opportunities in your inbox.
Tool #2 — Score your idea
When comparing multiple ideas it’s better to give each one a detailed score. Use this table to score your idea, then read what it means at the bottom.
1. Self Conviction — Add 0 points for each
2. Crafted Pitch — Add 0.1 points for each
3. Thematic support — Add 0.2 points for each
To learn how to use this and other Lean Product Management topics join one of my , or contact us to organize a for your company .
4. Other’s Opinions — add 1 points for each
5. High level plans and estimates — Add 5 points for each
6. Anecdotal evidence — add 20 points for each
7. Market data — Add 100 points for each
8. User/Customer evidence — Add 500 points for each
9. Test results — Add 2000 points for each
10. Early launch results — Add 10,000 points for each
1 month after launch:
11. Late launch results — Give it a “Good Idea!” badge
Note: this is a generic list of tests that most software products can use. In your industry there may be others that are more relevant. The important thing is to decide how indicative they are and to put them into the right confidence bucket.
Results
0–5 points — Very low confidence — This idea is almost entirely based on opinions and theory rather than data and fact. Even the most experienced and successful product minds struggle to forecast which ideas will succeed. Google, Twitter, AirBNB, and Android were all rejected almost universally as unsustainable product ideas, while Google Wave, The Semantic Web, Apple’s Newton and Windows 8 Metro UI seemed like great ideas at the time. You should not assume that you, your managers, peers, investors or outside experts can do any better. Thinking through your ideas and getting others’ feedback is crucial, but don’t assume it’s sufficient — you need to get out of the building to find the opinions that matter.
Vision and strategy statements, as well as most industry analyst reports tend to be very high-level and abstract, and are just as bad at predicting the future. Riding the waves of Industry trends (for example VR or Wearables) or basing your idea on a current product/design paradigm (micro-apps? SoA?) doesn’t give it any more credibility either. Trends and buzzwords are way too simplistic to apply to every product, worse they tend to every few quarters. There’s no way to theorize your way into building a great product.
6–100 points — Low confidence — You’ve started checking the feasibility of the idea through cost estimates and a rough plan. You saw that business numbers add up and maybe even created a business model canvas or a business plan. That’s a great step forward. Beware of the , though — we tend to be overly optimistic about both cost and impact of our own ideas. Same goes for your business plan — it’s mostly guesswork and this point and needs to be validated and adapted to reality.
Anecdotal evidence is helpful (in fact many ideas stem from anecdotal evidence) — it shows that at least some people out there agree with the idea. However we humans can easily see patterns and trends in noise. Statistically speaking this is not much proof either. You’ll need to get more real data and listen to many more potential users to grow in confidence.
101–500 points — Medium-Low confidence — Surveys, smoke tests and competitive analysis give you initial outside data, but your confidence is still just medium-low because you’re working with small samples that can easily be skewed or misinterpreted. Still you’ve started learning and improving (or abandoning) your idea based on objective evidence — an important milestone.
501–2000 — Medium-High confidence — You’re using quantitative and qualitative research to test the main hypothesis of your idea. You should feel proud — most product teams don’t go this far and miss out on critical data and facts that could have significantly improved the product. If successful your confidence in the idea should be majorly boosted. Still, testing a simplified or partial version of the idea with small groups of users isn’t enough to confirm the idea is worth launching. Keep going!
2001–10,000 points — high confidence — Now you’ve gone the extra mile to thoroughly test the idea, by now an early version of the product, with bigger groups of real users for longer duration of time. No longer an experiment in the lab, this is as close as it gets to the real thing. If you got good results here you should feel fairly confident you have a winner — launch it!. Still, sometimes statistics or an unexpected snafu can play a nasty trick on us, so be optimistic but watchful.
10,000+ points — very high confidence — Congratulation — the idea is now a launched! Still, in the weeks and months after launch there’s still some level of uncertainty about how the product is performing as well as novelty effects. This is not the time to let your guard down — keep processing the data and interviewing people to make sure you’re not missing anything.
The “Good Idea” badge — You made it, you can confidently say you made a dent in the universe and improved people’s lives, even if in a small way.
Obviously you don’t have to run every idea though every test in the list. Certainly for big ideas that require substantial investment it is good idea to to go through the test groups and perform at least a couple of things in each. Some data-driven companies like Netflix and Booking.com skip the early conviction/thematic-support/pitch phases altogether and empower their teams to A/B test almost anything. Other companies rely much more on qualitative research. Either way, doing more, especially of the mid and late tests, is very important.
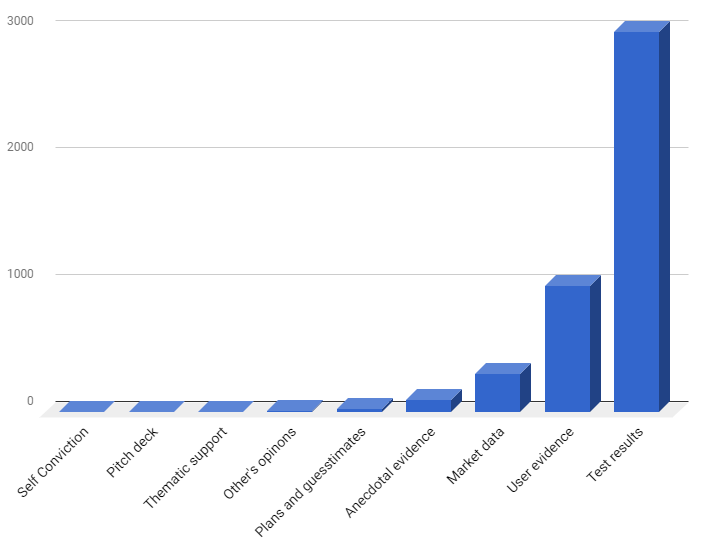
Here’s what a successful run might look like.

You can see that confidence level stays very low for awhile and then grows at exponential rate as hard evidence is collected. Most ideas will not get to this point and will be either abandoned or modified along the way, but that’s just how it needs to be.
Why is this Important?
All too often I see companies going all-in on a project armed with very little supporting evidence, usually trusting gut feeling, anecdotal evidence or at best sporadic market data (“a survey we ran shows that X% users want this feature”) — a score of 100 points or less. Worse, corporate execs seem exempt from even the most basic validation and can greenlight an 18-month project solely on the basis of self-conviction, “market data” or a strong pitch — a score of 5 points or less. This is a highly destructive pattern that is not only wasting time, money and energy, but is also highly demoralizing for employees and middle management. It just seems unfair and wasteful to work on a death-march project that is going nowhere while other, potentially better, ideas are left on the sideline just because they didn’t gain favor with management.
Similarly many startup funding decisions are done in a non-systematic way, favoring founder profiles, gut feeling and non-conclusive data over hard evidence.
By not looking confidence-scoring projects we’re also likely to underestimate or overestimate risk. For example companies trying to build an innovation portfolio, say with a 70/20/10 innovation mix, often fail to evaluate the risk inherent in their core projects and are thus failing to manage risk properly.
Using evidence-based scoring can simplify a lot of these investment decisions and make for a more systematic and transparent way to move forward — if an idea passes a validation phase it allowed to get more funds — just enough to move through the next phase, otherwise it is stopped. This allows for cheap exploration of many more ideas and for launch of the ones that are genuinely high-impact.
Common objections to evidence-based development
People with the “just do it” execution-biased mindset usually raise these objections:
Itamar Gilad () is a product consultant helping tech companies build products that deliver and capture tremendous value. He specializes in product strategy, product market fit, growth and innovation. Previously he was lead product manager at Google, Microsoft and a number of startups.
Want to print your doc?
This is not the way.
This is not the way.
Try clicking the ··· in the right corner or using a keyboard shortcut (
CtrlP
) instead.