Skip to content
Share
Explore

 Rituals for hypergrowth: An inside look at how YouTube scaled
Rituals for hypergrowth: An inside look at how YouTube scaled
A peek inside how YouTube tackled the 2008 to 2014 hypergrowth years with a unique set of rituals for everything from strategic planning to effective meetings.

Author’s note: This document was originally written in 2015 (see ), and reflects processes from my time co-leading the YouTube team from 2008-2014. As I left in 2014, I was asked by a number of folks to write down some of the key processes we used as we scaled through that hypergrowth period. I’ve since decided to scale this project and research rituals from many other great leaders and companies. This research is being compiled into a book called . If you’d like to read more and/or participate in the book, please join the braintrust here: . In the meantime, enjoy this historical perspective!
A snapshot of the YouTube cadence
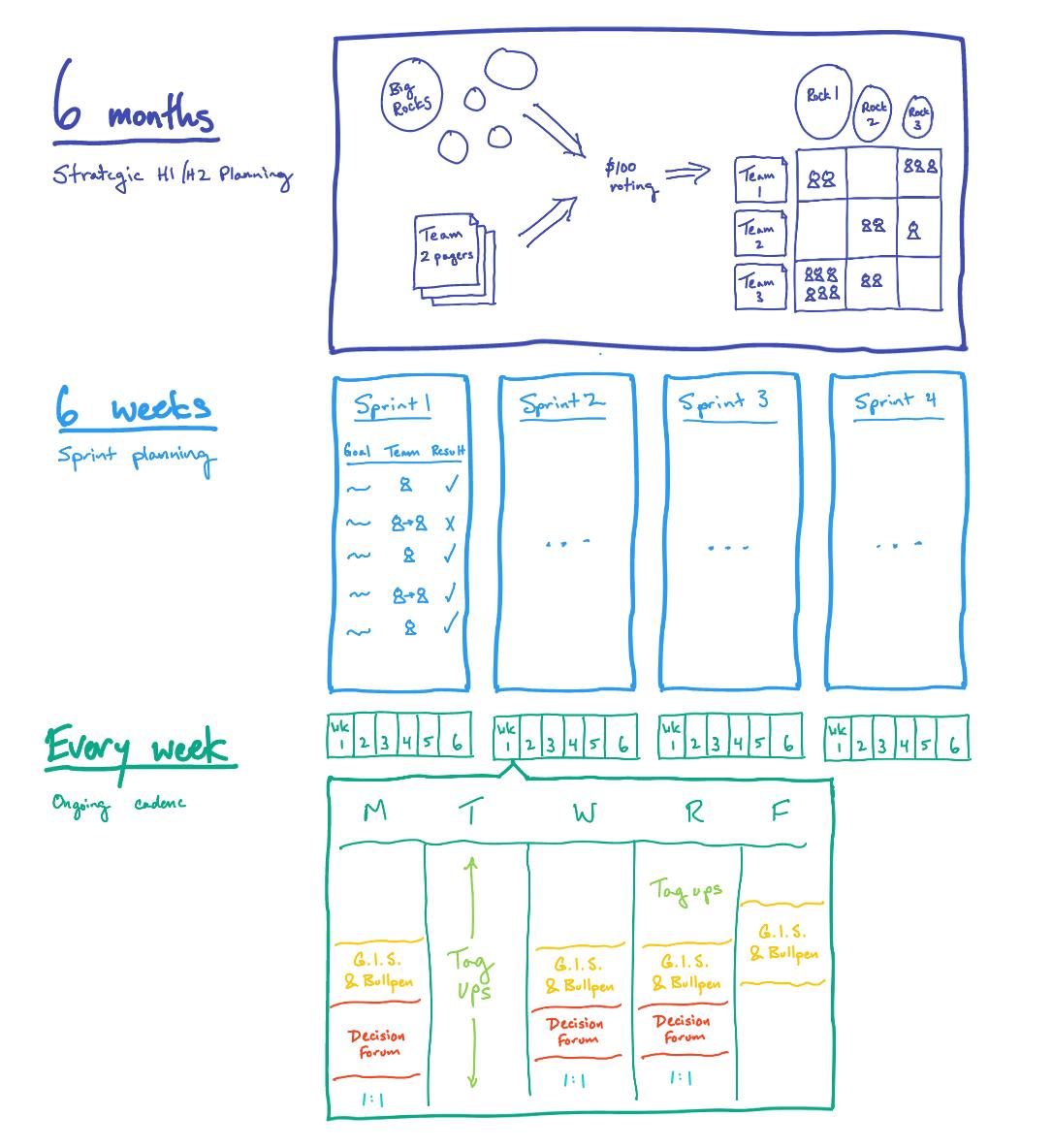
: 6-month strategic planning and 6-week sprints
Read on if...
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ⋯ next to your doc name or using a keyboard shortcut (
CtrlP
) instead.