Skip to content
Share
Explore
Horizontal Pod AutoScaling for Browserless
 Background and Context
Background and Context
Background and Context
What is Browserless?
What are the metrics we are interested in?
How does Browserless work right now?
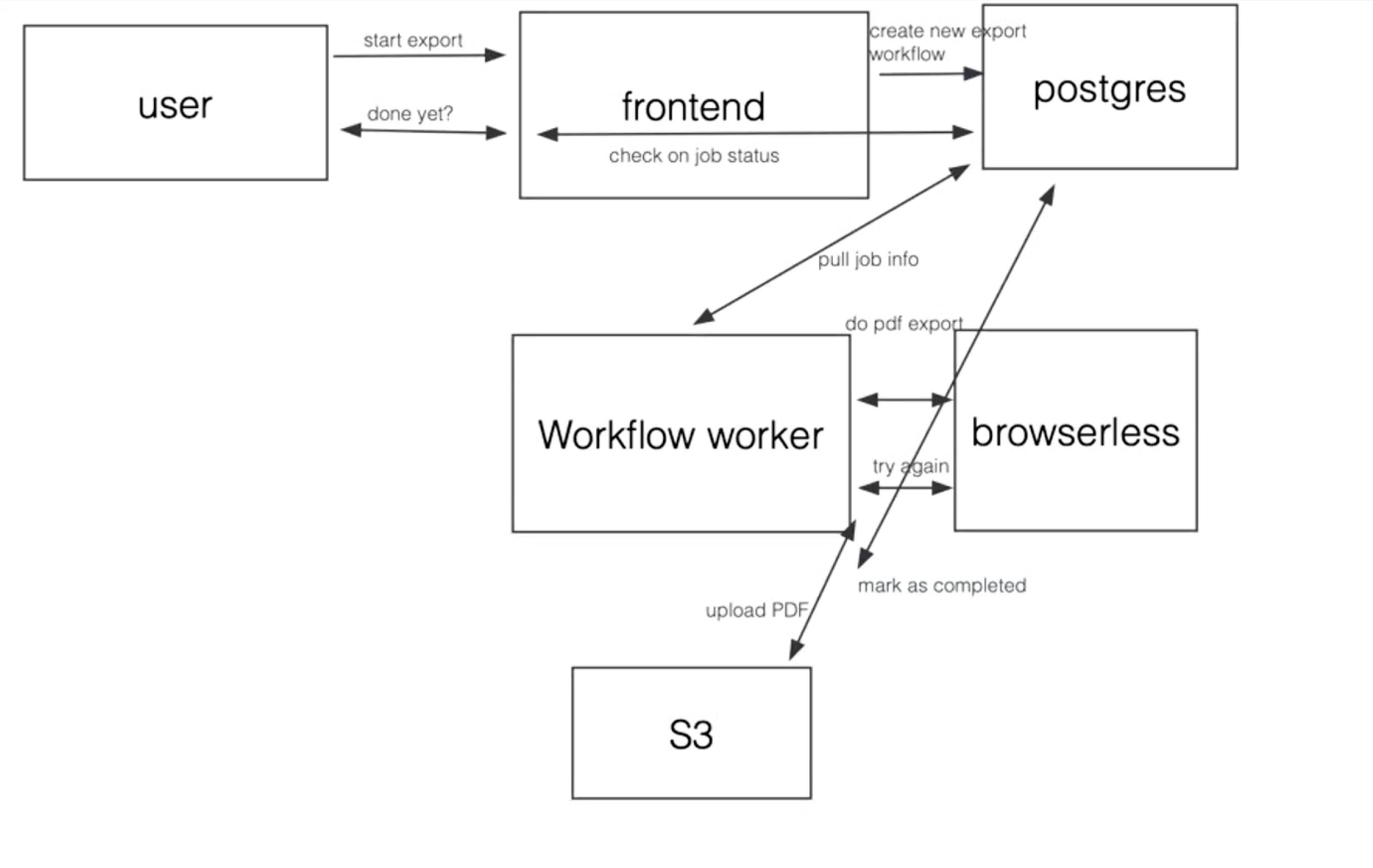
From the picture, there is bunch of new things and some of them autoscale while some do not.
Issues with this model:
Want to print your doc?
This is not the way.
This is not the way.

Try clicking the ⋯ next to your doc name or using a keyboard shortcut (
CtrlP
) instead.