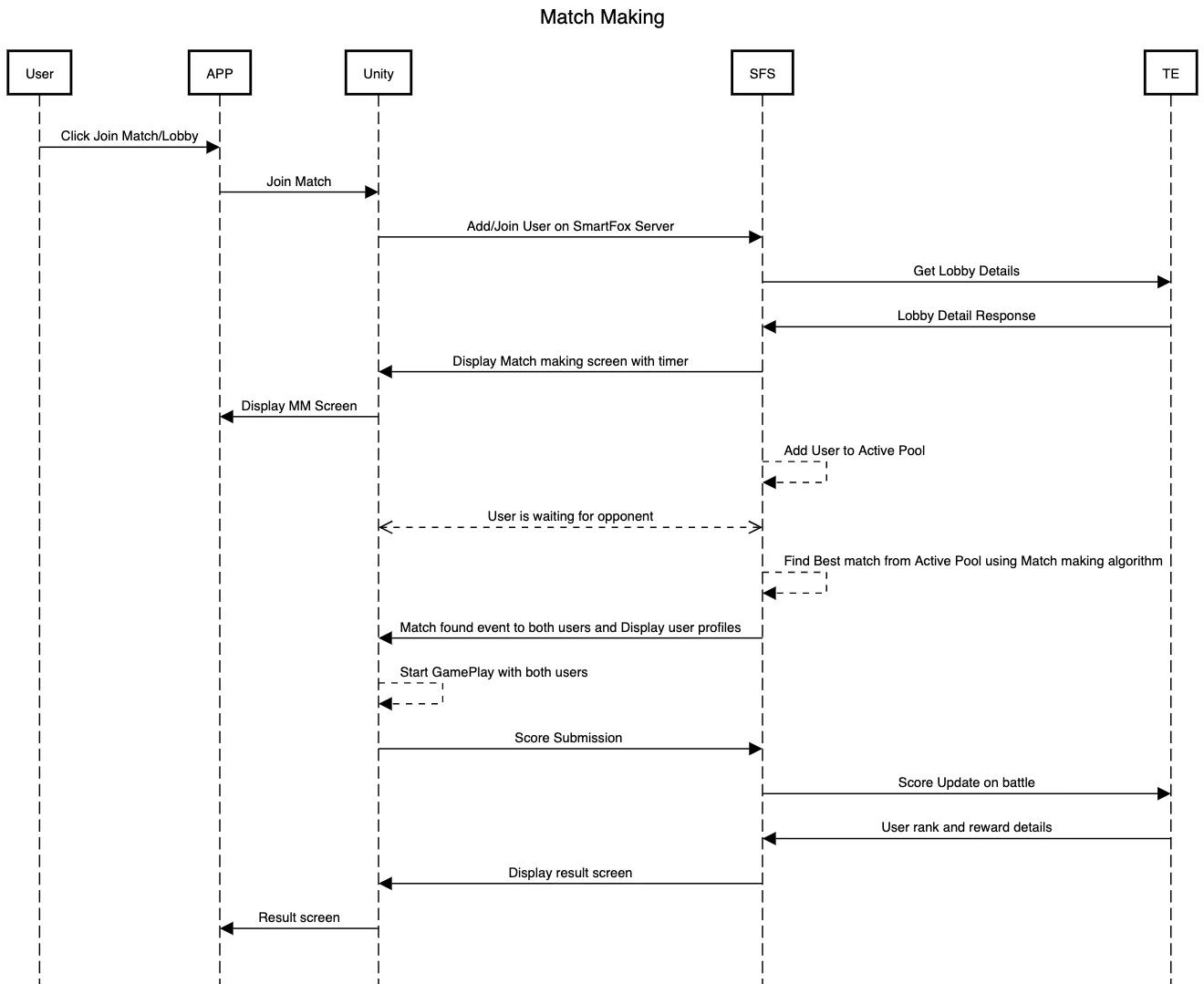
Why - Levers that we have → win rates, onboarding can solve the low D1 retention for new users
Win rates → need to maintain equilibrium, if low, users churn, if high, users suck liquidity
Current ELO system → unoptimised → takes long time to converge, only takes win loss into consideration, doesn’t work for new users, new users might be skilled as casual games
Study on churn of users with WWW to LLL → massive difference
Can we improve the Algorithm?
Pointwise user matching in real time →
optimise - > P(Win| [u1,u2])
data collection - data symmetrical in nature as we only have win loss, less than 1% draws.
u1 → in game features, recency, atv, win streaks, platform statistics
Base model - Logistic Regression
2. Catboost
The model needs to deployed on Game Server smart fox → java server, limited by how fast the iterations can be as worst case number of combinations can be nc2
Which Model is better?
offline metric → accuracy/ROC, but a threshold metric, not very useful → we want to optimise for game to be close to 0.5 prob
% of users predicted correctly in 40-60% bucket → very useful, as same can be tracked in real time
Elo pred vs model pred → 0.5 threshold
Simulation system - How many games can we effect? Came close to 40% where a better game can be found in <5 sec wait time
Model Deployment -
Performance testing for Catboost/LR - should be able to handle the twice the concurrency of our top game, 4x during IPL, without breaking SLA for wait time → average wait time, model prediction time + search time
Feature store → as soon as user enters the game, fetch the features
LR → use zkconfig for weights and multiply in realtime
catboost → pipeline for training →save in cbm format(usable in java) → Mlflow tracking → game server checks every 6 hours if any new model available through mlflow api → loads the model
5. Optimisation -
start with search for game for user in probability (0.4,0.6), whoever matches the criteria, match, don’t wait for nc2 combinations
model works after at least 3 games, hence split queue into new and old users, if no game in new user queue, shift to old with all features as 0
realised no point of doing matching during low concurrency hours, expand the range to make it fifo- dynamic config based on concurrency → simple rule engine worked for us
6. expand search every 5 seconds
Model monitoring -
Check for data drift → eurybia - model with AUC 0.5
feature store health → went down which brought the game down
model health → degredation in user predicted correctly in 40-60 bucket
Experimentation -
on-off experimentation → queue split results in concurrency split, hence results will have bias
slowdown experiment → how much does wait time matters → 3-4% GPU drop if increase of wait time of 50th percentile from 2sec to 5sec
power of experiment → same calculation, paired t-test for calculation
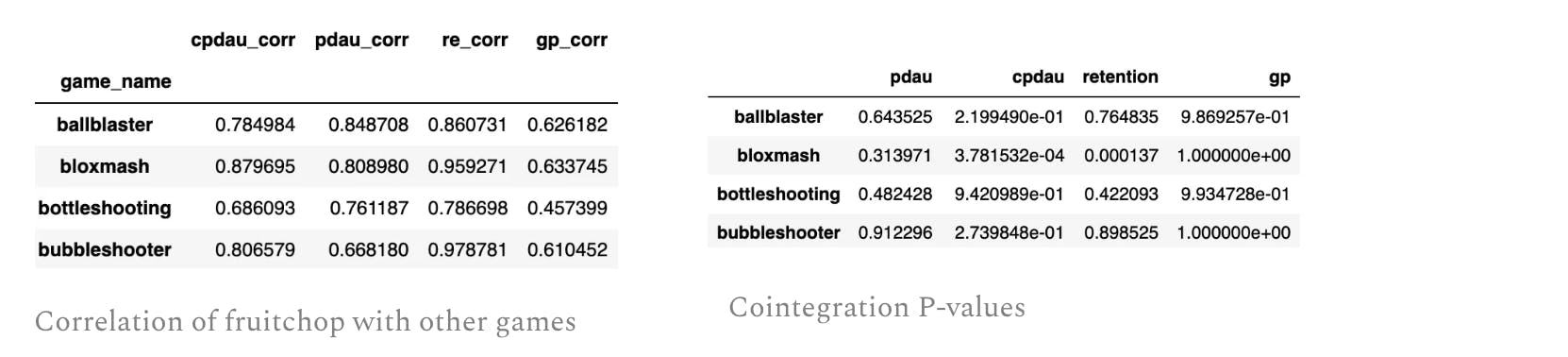
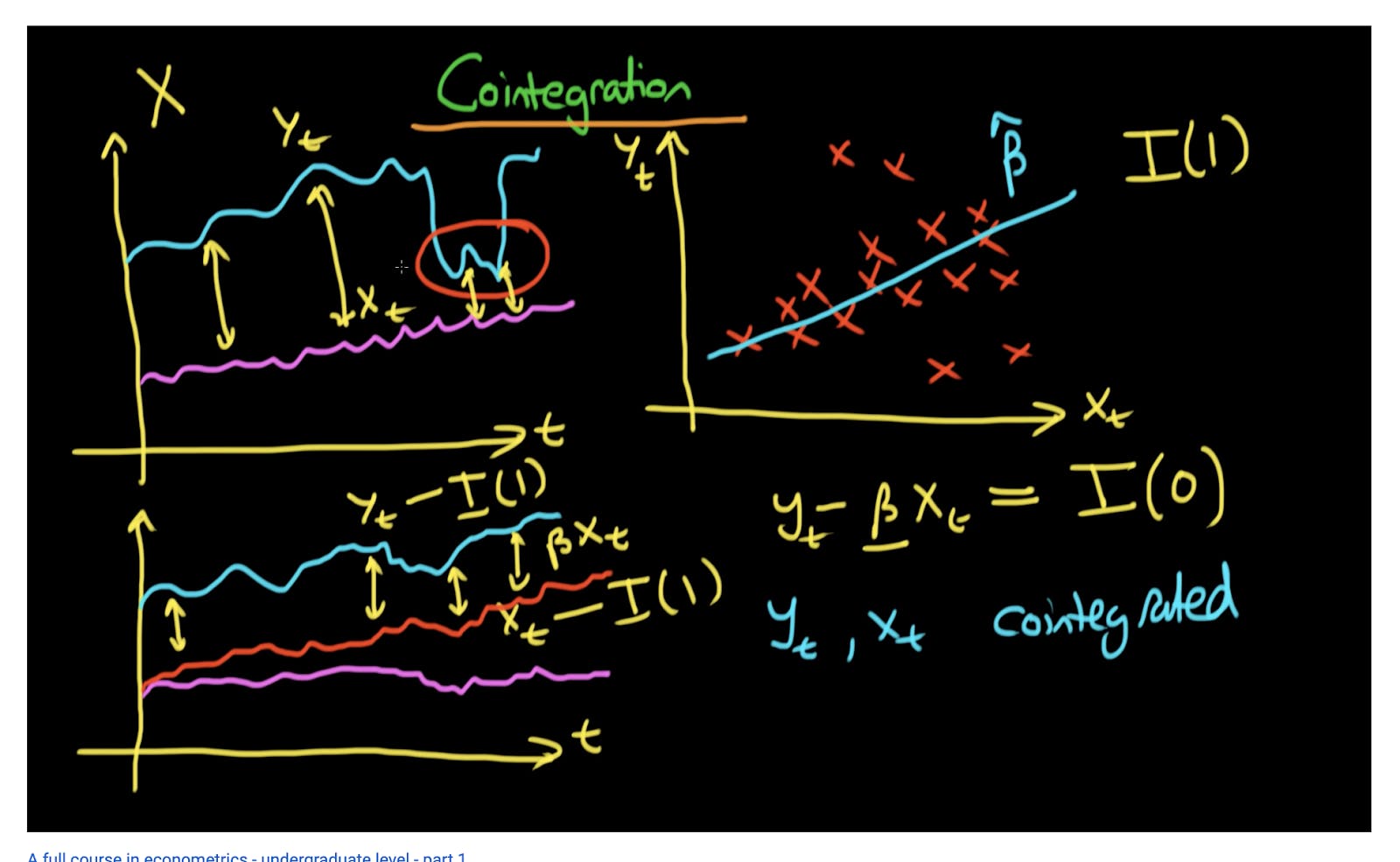
for removal of bias, get similar games → use correlation and cointegration
Biggest hurdle -
Failure to build single model for all games - score vs turn based, number of features that were empty
chance factor in games → configs
Want to print your doc? This is not the way.
Try clicking the ⋯ next to your doc name or using a keyboard shortcut (